The SIGdial 2023 organisers wanted a panel at the jointly held SIGdial 2023 and INLG 2023 conferences in Prague that took place last week. Svetlana Stoyanchev, as PC Chair in charge of it, proposed “Social impact of LLMs”. It was to follow the keynote talk by Ryan Lowe of OpenAI, the company behind the popular ChatGPT and also Whisper for speech, and he also would participate. I ended up in the panel as well (coming from the NLG angle of the matter), as did Ehud Reiter from the University of Aberdeen (UK) and Malihe Alikhani from Northeastern University (USA), with David Traum from the University of Southern California (USA) as moderator.
There was to be a 3-5 minutes opening statement by each panel member, which I had duly prepared for, but that did not happen. What happened first, was an unassuming 1-liner with name, affiliation, and area of specialisation. It then proceeded with questions the likes of “can you provide your view on how LLMs benefit society?”, “What is more important: factualness or fluency?”, and “which ethical concerns about LLMs are overstated?”.
I didn’t get on the panel for that sort of stuff. I was cajoled into saying ‘yes’ to the invitation because I already had compiled a partial list of social issues with LLMs. I’m teaching a module on “social issues and professional practice” to first-years in computer science at UCT and touched upon it in late July and early August at the start of the semester and I had mentioned some of it at a research ethics workshop at UCT. Note that ‘issues’ can be interesting and provide ideas for new research projects, provided they’re not inherent limitations of the theory, method, technique, tool, or practice.
As preparation for the panel, I tried to structure the list into a taxonomy of sorts to try to maximise information density in the short time I thought I would have. So when the moderator opened the floor for questions from the audience and no-one queued up instantly, I jumped in the gap. It might help to get the audience into action, too, or so I thought. And someone had to state the unpleasantries and challenges. So here’s that taxonomy-like list of social issues I managed to mention (in a nutshell and still incomplete):
1. In creation of LLMs
1.1 Resource usage (sensu climate change issues):
1.1.1 Electricity use for the computations training the LLMs;
1.1.2 Water use, used in data centre cooling where the computation takes place.
1.2 Exacerbating disparities, in that the less well off can’t compete with the rich corporations in The North and end up crowded out and as consumers only (and possibly also some colonialism, as noted by the speech researchers on Maori w.r.t. OpenAI’s Whisper).
1.3 Data (text) collection, notably regarding:
1.3.1 IP/copyright issues of the text ingested to generate the LLM;
1.3.2 The lack of trust (or the angst) on what data went and go into the LLMs (the ‘could be your emails, googledocs, sharepoint files etc.’), that no-one was asked whether they consented to their content being grabbed for that purpose, and when some would have disapproved of inclusion if they could, there’s the powerlessness in that it seems one neither can opt out nor verify if one’s text was excluded if opt-out were to be possible.
1.4 Psychological harm done unto the ‘garbage collectors’, such as the Kenyans in clickfarms, who are the manual labourers hired to remove the harmful content so that the system’s responses are clean and polite.
2. In content of LLMs
2.1 Bias, amplifying the bias in the source text the LLM trained on and that may be undesirable (e.g., gender).
2.2 Cultural imperialism:
2.2.1 Coverage/performance disparities. The LLM has ingested more from one region than another, so its output may not be relevant to the locale (say, to people in the RSA) or culture where it is used but rather output something that is applicable to people in the USA as if that were valid for the whole world;
2.2.2 Language. Whose language does it use in the interaction? On pushing out language varieties and dialects that are less well-represented in the training dataset, reducing diversity in expression, and steering towards homogenization.
3. In use of LLMs
3.1 Work:
3.1.1 It creates more work without getting extra resources for it;at least so far it has created more work for, among others, us lecturers than it purportedly would save (as if we didn’t have enough to do already);
3.1.2 It puts people out of jobs; this is for many a novel computing technique and should be managed but isn’t.
3.2 Information-seeking behaviour affecting democracy. The ‘one answer’ versus equally easy accessible answer options to assess multiple sources as part of information-seeking in democratic discourse, which is problematic due to fabrications (‘hallucinations’) and being fickle in property (content) dropping and an LLM may be amenable to manipulation for use as a propaganda machine.
3.3 Learning avoidance. There’s a difference between using LLMs as time-saver when one has the skill versus skipping learning competencies at school and university, such as writing and summarisation of course material when learning a subject.
3.x [there surely is more but I didn’t even have enough time to elaborate on item 3.3 already.]
The list in my lecture and workshop slides also included issues with misinformation, disinformation, privacy, and the unclear culpability attribution when there are bugs in the code it generates, which I hadn’t gotten around to include due to time constraints.
I can very well imagine the list will change, not only ending up longer, but also that more research may solve some of the issues so they can be removed. For instance, currently, language varieties descend into getting mixed onto one cocktail (they also did when David Traum tried with several Englishes) but it’s an interesting research question how one can (re)train an LLM to detect them in the training corpus and output it correctly, be this for written text or speech. It does not sound like an insurmountable problem to solve. Fear may be addressed with openness and education; policies might address some others.
Rotating Kafka head/disco ball in the city centre of Prague. (Source: I took it a few days before the INLG’23 conference)
While I was quickly going through my list, one attendee had walked over to the microphone and so I ended it at item 3.3. The question was about the impact of LLMs on the research community. The panel was called closed soon thereafter and lively comments followed when we all strolled into the conference welcome reception that took place at the same venue. I was pleased to hear those comments. More public debate in the panel session, however, would have been better for everyone compared to relegating it to the reception. Whether the muted response during the panel session was due to it having been a long day already—a great keynote talk by Emmanuel Dupoux, two long-paper sessions with interesting research, a poster session, and Ryan’s keynote—or due to it being recorded or for some other reason, I don’t know. Perhaps it is also up for debate whether it was wise to speak up. But no-one saying anything about some of the challenges with the social impact of LLMs in society was, in my view, not an acceptable option either.
To close off this blog post, I must note that there are more lists on social issues with LLMs and there’s quite some overlap between those resources and the taxonomy-like list described above. Among others: I can suggest you read this or that paper, or, if you’re short on time, have a look here or here that all have more explanatory text and references than this blog post.
How do you specify declaring content-of-interest or selecting content from a database or RDF triple store with the aim to convert that data into natural language text? Where that content may be either individual objects or classes or both, the relations that hold between them, and even functions to compute stuff from it? To be able to store such a specification and build larger ones from smaller ones? And that by possibly anyone, in their own language if they so wish? They are non-trivial broad requirements for, at least, the so-called “abstract representation” language for Abstract Wikipedia [Vrandecic21], with the data store being Wikidata (an RDF triple store that currently runs on Blazegraph). Examining related work, it turned out that no such language exists, so we set out to develop one.
Fortunately, we had an idea about how to go about designing a modelling language [FillottraniKeet21], but theory is not the same as praxis, and it hadn’t been tested with a real use case just yet, and a different type of modelling at that. One might as well try to kill two birds with one stone, and that is indeed what we did. The outcome is described in an extended technical report [ArrietaEtal23], which is, admittedly, still quite research-oriented, although we tried to explain things more than we normally do in scientific publications. We dubbed our language CoSMo, from Content Selection Modeling language. It makes one component of that magic box called “article generation”, as part of the overall orchestration of Abstract Wikipedia components, clear and precise.
CoSMo’s intended place in the high-level outline of Abstract Wikipedia. (It can also be usedoutside the AW context).
The remainder of this blog post contains a quick non-technical digest of that 32-page report.
The preparations: figuring out the requirements
In the Abstract Wikipedia NLG team that focuses on the natural language generation (NLG) specifically, we all knew we needed something between the content of Wikidata and the natural language text as output. The content of that text would be represented abstractly, in a structured fashion, i.e., the so-called “abstract representation” of that, which would be written in self-contained pieces, called “constructors”. So far so good. Then there came had several stakeholder meetings with the Abstract Wikipedia team and other interested Wikipedians in September and October 2022. We discovered there were wildly different assumption about the constructors, what they were for, and what one should be able to model with them.
Taking a step back, we all devised examples, and two proof-of-concepts were experimented with (Nina/Udiron by Mahir Morshed and a Scribunto-based implementation by Ariel Gutman). From there, it was possible to extract requirements for language design. Some of this was written up in a discussion document and put online late November 2022. It did not receive any feedback. More examples and implicit requirements were collected, including more ‘reasoning backwards’ from sample desired output to what data would need to be in Wikidata to be able to get such as sentence out of it, to help inform what a constructor needs to have that would help bridge the two extremes. Various features were elaborated on and discussed in an Abstract Wikipedia open meeting of the NLG group (recorded). It was February 2023 already.
It had become clear that not everything could reasonably be done all at once, nor would one want to, so Pablo Fillottrani, Kutz Arrieta, and I made the decision to take one step at a time: the first step in the natural language generation pipeline is content selection, not also all sorts of linguistic structures that one can find later on in the generation pipeline. From these preliminaries, we selected a list of design principles and features we though made most sense (see section 3.2 of the technical report for details), and moved on to the next step.
Defining a language
With the parameters and requirements in hand, it should have been straightforward to define the content selection language. It wasn’t. Sometimes, a requirement can be met in more than one way and we also wanted a graphical counterpart to any textual version, which also caused a few iterations to make a constructor look pretty and easily readable. We tried to reuse existing icons as much as possible, so that then at least a segment of users may already be familiar with them. For instance, the diamond-shape from UML for composition of smaller constructors into larger ones. The report’s tables 1-3 list the icons for the elements, connectors and constraints, respectively, their respective longform notation when it’s rendered in English, and a usage comment. Here are the elements:
The syntax needed a semantics, which it got (see also Table 4 of the report). Working on the details and example diagrams, we admitted it did need a grammar as well, to make sure that constructors are specified in the way they’re supposed to, and to make the step towards an implementation easier. Those details can be found in Appendix A near the end of the report.
Behind the pretty graphics and longform renderings, it looks uninviting and not intended for human consumption, as is the case for most of Wikidata and Wikifunctions, due to the aim for natural language independence, or at least some form of multilingualism. Here’s an example of the not-for-humans specification of a constructor, where the CSMxxx numbers are elements in CoSMo, and Q and P items exist in Wikidata:
In a text-based user interface, the identifiers are to be replaced with their respective labels in the chosen natural language. In a graphical user interface, the CSMxxx elements are to be rendered graphically. An example of a diagram that illustrates a case where three constructors are combined is shown next:
The CSMxxx identifiers were mapped to Wikidata items where possible at present, and from there we obtain the human-readable names, which are listed in the technical report’s Table 5 for English, Spanish, and Basque.
Evaluation
There are several strategies to determine whether the language is any good. The first step is the check whether it meets the requirements it is supposed to meet. CoSMo does (see section 4.2). The second step is the ‘can one create a constructor?’ (without too much effort) and, pushing that further: ‘is it expressive enough to represent the examples we started out with?’. The answer to the first question is a resounding Yes. Further to the previous image, here’s one of those in CoSMo longform textual notation where the elements are rendered in English and in Spanish (Appendix C has more examples):
The answer to the second question is trickier. In the very strict sense, the answer is No, which doesn’t sound good on first reading. The first reason why it’s not as bad as it sounds, is that some examples from last year mixed content and natural language features, which was precisely what we needed to disentangle to make constructors manageable, usable, and reusable. The second reason was that some examples were making assumptions about Wikidata content but where it was represented differently or it should be possible to delegate the task to the recently launched Wikifunctions. Here’s a section of the San Francisco example from [Vrandecic21] in CoSMo graphical notation, which contains a function for computing the ranking on-the-fly rather than hard-coding the ranking (the Z item number is made up and such a function is still to be added to Wikifunctions that launched just this month).
Finally, we conducted a feature comparison of CoSMo against similar-looking modelling languages, and, indeed, it is one of a kind.
In closing
Is this all there is and can a system generate natural language text with it already? No, sorry, things don’t go that fast when only limited resources are at one’s disposal. A few other parts of the natural language generation pipeline are available for different NLG approaches and CoSMo fills a gap in the procedure. Not only that, CoSMo can just as well be used outside Abstract Wikipedia and even when no natural language generation is in sight. From a data store design perspective, CoSMo offers an abstract representation, i.e., a modelling language, of a data store view specification, alike for SQL VIEW statements, but then regardless whether that is for a database, an RDF triple store, or even some JSON thing that tries to pass for a database. Or, from a graph algorithm viewpoint: CoSMo makes defining subgraphs (among other things) more accessible to a broader user base.
Last, but not least: no, LLMs will not fix it for you. There are a few technical hick-ups at present (read a discussion of LLM-to-SPARQL), but even if/when they are solved: SPARQL itself does not meet all the requirements for the constructor specification language, hence, an LLM-to-SPARQL app does not either. (see Table 6 and compare the WONDER, VSB and RDF Explorer columns with CoSMo for details.)
Finally, CoSMo is a concrete proposal – admittedly, one that we hope will be adopted by the Abstract Wikipedia project – and we look forward to feedback!
The trip to the Empirical Methods in Natural Language Processing 2022 conference is certainly one I’ll remember. The conference had well over 1000 in-person people attending what they could of the 6 tutorials and 24 workshops on Wednesday and Thursday, and then the 175 oral presentations, 654 posters, 3 keynotes and a panel session, and 10 Birds of Feather sessions on Friday-Sunday, which was topped off with a welcome reception and a social dinner. The open air dinner was on the one day in the year that it rains in the desert! More precisely on the venue: that was the ADNEC conference centre in Abu Dhabi, from 7 to 11 December.
With so many parallel sessions, it was not always easy to choose. Although I expected many presentations about just large language models (LLMs) that I’m not particularly interested in from a research perspective, it turned out it was very well possible to find a straight road through the parallel NLP sessions with research that had at least added an information-based or a knowledge-based approach to do NLP better. Ha! NLP needs structured data, information, and knowledge to mitigate the problems with hallucinations in natural language generation – elsewhere called “fluent bullshit” – that those LLMs suffer from, among other tasks. Adding a symbolic approach into the mix turned out to be a recurring theme in the conference. Some authors tried to hide a rule-based approach or were apologetic about it, so ‘hot’ the topic is not just yet, but we’ll get there. In any case, it worked so much better for my one-liner intro to state that I’m into ontologies having been branching out to NLG than to say I’m into NLG for African languages. Most people I met had heard of ontologies or knowledge graphs, whereas African languages mostly drew a blank expression.
It was hard to choose what to attend especially on the first day, but eventually I participated in part of the second workshop on Natural Language Generation, Evaluation, and Metrics (GEM’22), NLP for positive impact (NLP4PI’22), and Data Science with Human-in-the-Loop (DaSH’22), and walked into a few more poster sessions of other workshops. The conference sessions had 8 sessions in parallel in each timeslot; I chose the semantics one, ethics, NLG, commonsense reasoning, speech and robotics grounding, and the birds of a feather sessions on ethics and on code-switching. I’ve structured this post by topic rather than by type of session or actual session, however, in the following order: NLP with structured stuff, ethics, a basket with other presentations that were interesting, NLP for African languages, the two BoF sessions, and a few closing remarks. I did at least skim over the papers associated with the presentations and referenced here, and so any errors in discussing the works are still mine. Logistically, the links to the papers in this post are a bit iffy: about 900 EMNLP + workshops papers were already on arxiv according to the organisers, and 828 papers of the main conference are being ingested into the ACL anthology and so its permanent URL is not functional yet, and so my linking practice was inconsistent and may suffer link rot. Be that as it may, let’s get to the science.
The entrance of the conference venue, ADNEC in Abu Dhabi, at the end of the first workshop and tutorials day.
NLP with at least some structured data, information, or knowledge and/or reasoning
I’ve tried to structure this section, roughly going from little addition of structured stuff to more, and then from less to more inferencing.
The first poster session on the first day that I attended was the one of the NLP4PI workshop; it was supposed to be for 1 hour, but after 2.5h it was still being well-attended. I also passed by the adjacent Machine translation session (WMT’22) that also paid off. There were several posters there that were of interest to my inclination toward knowledge engineering. Abhinav Lalwani presented a Findings paper on Logical Fallacy Detection in the NLP4PI’22 poster session, which was interesting both for the computer ethics that I have to teach and their method: create a dataset of 2449 fallacies of 13 types that were taken for online educational resources, machine-learn templates from those sentences – that they call generating a “structure-aware model” – and then use those templates to find new ones in the wild, which was on climate change claims in this case [1]. Their dataset and code are available on GitHub. The one presented by Lifeng Han from the University of Manchester was part of WMT’22: their aim was to see whether a generic LLM would do better or worse than smaller in-domain language models enhanced with clinical terms extracted from biomedical literature and electronic health records and from class names of (unspecified in the paper) ontologies. The smaller models win, and terms or concepts may win depending on the metric used [2].
For the main conference, and unsurprising for a session called “semantics”, it wasn’t just about LLMs. The first paper was about Structured Knowledge Grounding, of which the tl;dr is that SQL tables and queries improve on the ‘state of the art’ of just GPT-3 [3]. The Reasoning Like Program Executors aims to fix nonsensical numerical output of LLMs by injecting small programs/code for sound numerical reasoning, among the reasoning types that LLMs are incapable of, and are successful at doing so [4]. And there’s a paper on using WordNet for sense retrieval in the context of word in/vs context use, and on discovering that the human evaluators were less biassed than the language model [5].
The commonsense reasoning session also – inevitably, I might add – had papers that combined techniques. The first paper of the session looked into the effects of injecting external knowledge (Comet) to enhance question answering, which is generally positive, and more positive for smaller models [6]. I also have in my notes that they developed an ontology of knowledge types, and so does the paper text claim so, but it is missing from the paper, unless they are referring to the 5 terms in its table 6.
I also remember seeing a poster on using Abstract Meaning Representation. Yes, indeed, and there turned out to be a place for it: for text style transfer to convert a piece of text from one style into another. The text-to-AMR + AMR-to-text model T-STAR beat the state of the art with a 15% increase in content preservation without substantive loss of accuracy (3%) [7].
Moving on to rules and more or less reasoning, first, at the NLP4PI’22 poster session, there was a poster on “Towards Countering Essentialism through Social Bias Reasoning”, which was presented by Maarten Sap. They took a very interdisciplinary approach, mixing logic, psychology and cognitive science to get the job done, and the whole system was entirely rules-based. The motivation was to find a way to assist content moderators by generating possible replies to counter prejudiced statements in online comments. They generated five types of replies and asked users which one they preferred. Types of sample generated replies include, among others, to compute exceptions to the prejudice (e.g., an individual in the group who does not have that trait), attributing the trait also to other groups, and a generic statement on tolerance. Bland seemed to work best. I tried to find the paper for details, but was unsuccessful.
The DaSH’22 presentation about WaNLI concerned the creation of a dataset and pipeline to have crowdsourcing workers and AI “collaborate” in dataset creation, which had a few rules sprinkled into the mix [8]. It turns out that humans are better at revising and evaluating than at creating sentences from scratch, so the pipeline takes that into account. First, from a base set, it uses NLG to generate complement sentences, which are filtered and then reviewed and possibly revised by humans. Complement sentence generation (the AI part) involves taking sentences like “5% chance that the object will be defect free” + “95% that the object will have defects” to then generate (with GPT-3, in this case) the candidate sentence pairs “1% of the seats were vacant” + “99% of the seats were occupied”, using encoded versions of the principles of entailment and set complement, among the reasoning cases used.
Turning up the reasoning a notch, Sean Welleck of the University of Washington gave the keynote at GEM’22. His talks consisted of two parts, on unlearning bad behaviour of LLMs and then an early attempt with a neuro-symbolic approach. The latter concerned connecting a LLM’s output to some logic reasoning. He chose Isabelle, of all reasoners, as a way to get it to check and verify the hallucinations (the nonsense) the LLMs spit out. I asked him why he chose a reasoner for an undecidable language, but the response was not a direct answer. It seemed that he liked the proof trace but was unaware of the undecidability issues. Maybe there’s a future for description logics reasoners here. Elsewhere, and hidden behind a paper title that mentions language models, lies a reality of the ConCoRD relation detection for “boosting consistency of pre-trained language models” with a MAX-SAT solver in the toolbox [9].
Impression of the NLP4PI’22 poster session 2.5h into the 1h session timeslot.
There are (many?) more relevant presentations that I did not get around to attending, such as on dynamic hierarchical reasoning that uses both a LM and a knowledge graph for their scope of question answering [10], a unified representation for graph query language, GraphQ IR [11], and on that RoBERTa, T5, and GPT3 have problems especially with deductive reasoning involving negation [12] and PLOG table-to-logic to enhance table-to-text. Open the conference program handbook and search on things like “commonsense reasoning” or NLI where the I isn’t an abbreviation of Interface but of Inference rather, and there’s even neural-symbolic inference for graph parsing. The compound term “Knowledge graph” has 84 mentions and “reasoning” has 244 mentions. There are also four papers with “grammar induction”, two papers with CFGs, and one with a construction grammar.
It was a pleasant surprise to not be entirely swamped by the “stats/NN + automated metric” formula. I fancy thinking it’s an indication that the frontiers of NLP research already grew out of that and is adding knowledge into the mix.
Ethics and computational social science
Of course, the previously-mentioned topic of trying to fix hallucinations and issues with reasoning and logical coherence of what the language models spit out implies researchers know there’s a problem that needs to be addressed. That is a general issue. Specific ones are unique in their own way; I’ll mention three. Inna Lin presented work on gendered mental health stigma and potential downstream issues with health chatbots that would rely on such language models [13]. For instance, that women were more likely to be recommended to seek professional help and men to toughen up and get on with it. The GeoMLAMA dataset showed that not everything is as bad as one might suspect. The dataset was created to explore multilingual Pre-Trained Language Models on cultural commonsense knowledge, like which colour the dress of the bride is typically. The authors selected English, Chinese, Hindi, Persian, and Swahili. Evaluation showed that multilingual PLMs are not biased toward the USA, that the native language of a country may not be the best language to probe its knowledge (as the commonsense isn’t explicitly stated) and a language may better probe knowledge about a nonnative country than its native country. [14]. The third paper is more about working on a mechanism to help NLP ethics: modelling information change in science communication. The scientist or the press release says one thing, which gets altered slightly in a popular science article, and then morphs into tweets and toots with yet another, different, message. More distortions occurs in the step from popsci article to tweet than from scientist to popsci article. The sort of distortion or ‘not as faithful as one would like’? Notably, “Journalists tend to downplay the certainty and strength of findings from abstracts” and “limitations are more likely to be exaggerated and overstated”. [15]
In contrast, Fatemehsadat Mireshghallah showed some general ethical issues with the very LLMs in her lively presentation. They are so large and have so many parameters that what they end up doing is more alike text memorization and output that memorised text, rather than outputting de novo generated text [16]. She focussed on potential privacy issues, where such models may output sensitive personal data. It also applies to copyright infringement issues: if they return chunk of already existing text, say, a paragraph from this blog, it would be copyright infringement, since I hold the copyright on it by default and I made it CC-BY-NC-SA, which those large LLMs do not adhere to and they don’t credit me. Copilot is already facing a class action lawsuit for unfairly reusing open source code without having obtained permission. In both cases, there’s the question, or task, of removing pieces of text and retraining the model, or not, as well as how to know whether your text was used to create the model. I recall seeing something about that in the presentations and we had some lively discussions about it as well, leaning toward a remove & re-train and suspecting that’s not what’s happening now (except at IBM apparently).
Last, but not least, on this theme: the keynote by Gary Marcus turned out to be a pre-recorded one. It was mostly a popsci talk (see also his recent writings here, among others) on the dangers of those large language models, with plenty of examples of problems with them that have been posted widely recently.
Noteworthy “other” topics
The ‘other’ category in ontologies may be dubious, but here it is not meant as such – I just didn’t have enough material or time to write more about them in this post, but they deserved a mention nonetheless.
The opening keynote of the EMNLP’22 conference by Neil Cohn was great. His main research is in visual languages, and those in comic books in particular. He raised some difficult-to-answer questions and topics. For instance, is language multimodal – vocal, body, graphic – and are gestures separate from, alongside, or part of language? Or take the idea of abstract cognitive principles as basis for both visual and textual language, the hypothesis of “true universals” that should span across modalities, and the idea of “conceptual permeability” on whether the framing in one modality of communication affects the others. He also talked about the topic of cross-cultural diversity in those structures of visual languages, of comic books at least. It almost deserves to be in the “NLP + symbolic” section above, for the grammar he showed and to try to add theory into the mix, rather than just more LLMs and automated evaluation scores.
The other DaSH paper that I enjoyed after aforementioned Wanli was the Cheater’s Bowl, where the authors tried to figure out how humans cheat in online quizzes [17]. Compared to automated open-domain question-answering, humans use fewer keywords more effectively, use more world knowledge to narrow searches, use dynamic refinement and abandonment of search chains, have multiple search chains, and do answer validation. Also in the workshops days setting, I somehow also walked into a poster session of the BlackboxNLP’22 workshop on analysing and interpreting neural networks for NLP. Priyanka Sukumaran enthusiastically talked about her research how LSTMs handle (grammatical) gender [18]. They wanted to know where about in the LSTM a certain grammatical feature is dealt with; and they did, at least for gender agreement in French. The ‘knowledge’ is encoded in just a few nodes and does better on longer than on shorter sentences, since then it can use more other cues in the sentence, including gendered articles, to figure out M/F needed for constructions like noun-adjective agreement. That definitely is alike the same way humans do, but then, algorithms do not need to copy human cognitive processes.
NLP4PI’s keynote was given Preslav Nakov, who recently moved to the Mohamed Bin Zayed University of AI. He gave an interesting talk about fake news, mis- and dis-information detection, and also differentiated it with propaganda detection that, in turn, consists of emotion and logical fallacy detection. If I remember correctly, not with knowledge-based approaches either, but interesting nonetheless.
I had more papers marked for follow up, including on text generation evaluation [19], but this post is starting to become very long as it is already.
Papers with African languages, and Niger-Congo B (‘Bantu’) languages in particular
Last, but not least, something on African languages. There were a few. Some papers had it clearly in the title, others not at all but they used at least one of them in their dataset. The list here is thus incomplete and merely reflects on what I came across.
On the first day, as part of NLP4PI, there was also a poster on participatory translations of Oshiwambo, a language spoken in Namibia, which was presented by Jenalea Rajab from Wits and Millicent Ochieng from Microsoft Kenya, both with the masakhane initiative; the associated paper seems to have been presented at the ICLR 2022 Workshop on AfricaNLP. Also within the masakhane project is the progress on named entity recognition [20]. My UCT colleague Jan Buys also had papers with poster presentation, together with two of his students, Khalid Elmadani and Francois Meyer. One was part of the WMT’22 on multilingual machine translation for African languages [21] and another on sub-word segmentation for Nguni languages (EMNLP Findings) [22]. The authors of AfroLID show results that they have some 96% accuracy on identification of a whopping 517 African languages, which sounds very impressive [23].
Birds of a Feather sessions
The BoF sessions seemed to be loosely organised discussions and exchange-of-ideas about a specific topic. I tried out the Ethics and NLP one, organised by Fatemehsadat Mireshghallah, Luciana Benotti, and Patrick Blackburn, and the code-switching & multilinguality one, organised by Genta Winata, Marina Zhukova, and Sudipta Kar. Both sessions were very lively and constructive and I can recommend to go to at least one of them the next time you’ll attend EMNLP or organise something like that at a conference. The former had specific questions for discussion, such as on the reviewing process and on that required ethics paragraph; the latter had themes, including datasets and models for code-switching and metrics for evaluation. For ethics, there seems to be a direction to head toward, whereas the NLP for code-switching seems to be still very much in its infancy.
Final remarks
As if all that wasn’t keeping me busy already, there were lots of interesting conversations, meeting people I haven’t seen in many years, including Barbara Plank who finished her undergraduate studies at FUB when I was a PhD student there (and focussing on ontologies rather, which I still do) and likewise for Luciana Benotti (who had started her European Masters at that time, also at FUB); people with whom I had emailed before but not met due to the pandemic; and new introductions. There was a reception and an open air social dinner; an evening off meeting an old flatmate from my first degree and a soccer watch party seeing Argentina win; and half a day off after the conference to bridge the wait for the bus to leave which time I used to visit the mosque (it doubles as worthwhile tourist attraction), chat with other attendees hanging around for their evening travels, and start writing this post.
Will I go to another EMNLP? Perhaps. Attendance was most definitely very useful, some relevant research outputs I do have, and there’s cookie dough and buns in the oven, but I’d first need a few new bucketloads of funding to be able to pay for the very high registration cost that comes on top of the ever increasing travel expenses. EMNLP’23 will be in Singapore.
[3] Tianbao Xie, Chen Henry Wu, Peng Shi, Ruiqi Zhong, Torsten Scholak, Michihiro Yasunaga, Chien-Sheng Wu, Ming Zhong, Pengcheng Yin, Sida I. Wang, Victor Zhong, Bailin Wang, Chengzu Li, Connor Boyle, Ansong Ni, Ziyu Yao, Dragomir Radev, Caiming Xiong, Lingpeng Kong, Rui Zhang, Noah A. Smith, Luke Zettlemoyer and Tao Yu. UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models. EMNLP’22.
[4] Xinyu Pi, Qian Liu, Bei Chen, Morteza Ziyadi, Zeqi Lin, Qiang Fu, Yan Gao, Jian-Guang LOU and Weizhu Chen. Reasoning Like Program Executors. EMNLP’22
It’s hardly ever entirely one extreme or the other in natural language generation and controlled natural languages. Rarely can one get away with simplistic ‘just fill in the blanks’ templates that do not do any grammar or phonological processing to make the output better; our technical report about work done some 17 years ago was a case in point on the limitations thereof if one still needs to be convinced [1]. But where does NLG start? I agree with Ehud Reiter that it isn’t about template versus NLG, but a case of levels of sophistication: the fill-in-the-blank templates definitely don’t count as NLG and full-fledged grammar-only systems definitely do, with anything in-between a grey area. Adding word-level grammatical functions to templates makes it lean to NLG, or even indeed being so if there are relatively many such rules, and dynamically creating nicely readable sentences with aggregation and connectives counts as NLG for sure, too.
With that in mind, we struggled with how to name the beasts we had created for generating sentences in isiZulu [2], a Niger-Congo B language: nearly every resultant word in the generated sentences required a number of grammar rules to make it render sufficiently well (i.e., at least grammatically acceptable and understandable). Since we didn’t have a proper grammar engine yet, but we knew they could never be fill-in-the-blank templates either, we dubbed them verbalisation patterns. Most systems (by number of systems) use either only templates or templates+grammar, so our implemented system [3] was in good company. It may sound like oldskool technology, but you go ask Meta with their Galactica if a ML/DL-based approach is great for generating sensible text that doesn’t hallucinate… and does it well for languages other than English.
That said, honestly, those first attempts we did for isiZulu were not ideal for reusability and maintainability – that was not the focus – and it opened up another can of worms: how do you link templates to (partial) grammar rules? With the ‘partial’ motivated by taking it one step at a time in grammar engine development, as a sort of agile engine development process that is relevant especially for languages that are not well-resourced.
We looked into this recently. There turn out to be three key mechanisms for linking templates to computational grammar rules: embedding (E), where grammar rules are mixed with the templates specifications and therewith co-dependent, and compulsory (C) and partial (P) attachment where there is, or can be, an independent existence of the grammar rules.
Attachment of grammar rules (that can be separated) vs embedding of grammar rules in a system (intertwined with templates) (Source: [6])
The difference between the latter two is subtle but important for use and reuse of grammar rules in the software system and the NLG-ness of it: if each template must use at least one rule from the set of grammar rules and each rule is used somewhere, then the set of rules is compulsorily attached. Conversely, it is partially attached if there are templates in that system that don’t have any grammar rules attached. Whether it is partial because it’s not needed (e.g., the natural language’s grammar is pretty basic) or because the system is on the fill-in-the-blank not-NLG end of the spectrum, is a separate question, but for sure the compulsory one is more on the NLG side of things. Also, a system may use more than one of them in different places; e.g., EC, both embedding and compulsory attachment. This was introduced in [4] in 2019 and expanded upon in a journal article entitled Formalisation and classification of grammar and template-mediated techniques to model and ontology verbalisation [5] that was published in IJMSO, and even more detail can be found in ZolaMahlaza’s recently completed PhD thesis [6]. These papers have various examples, illustrations how to categorise a system, and why one system was categorised in one way and not another. Here’s a table with several systems that combine templates and computational grammar rules and how they are categorised:
Source: [5]
We needed a short-hand name to refer to the cumbersome and wordy description of ‘combining templates with grammar rules in a [theoretical or implemented] system in some way’, which ended up to be grammar-infused templates.
Why write about this now? Besides certain pandemic-induced priorities in 2021, the recently proposed template language for Abstract Wikipedia that I blogged about before may mix Compulsory or Partial attachment, but ought not to permit the messy embedding of grammar in a template. This may not have been clear in v1 of the proposal, but hopefully it is a little bit more so in this new version that was put online over the past few days. To make that long story short: besides a few notes at the start of its Section 3, there’s a generic description of an idea for a realization algorithm. Its details don’t matter if you don’t intend to design a new realiser from scratch and maybe not either if you want to link it to your existing system. The key take-away from that section is that there’s where the real grammar and phonological conditioning stuff happens if it’s needed. For example, for the ‘age in years’ sub-template for isiZulu, recall that’s:
The template language sets some boundaries for declaring such a template, but it is a realiser that has to interpret ‘keywords’, such as root, concord, and RelativeConcord, and do something with it so that the output ends up correctly; in this case, from ‘year’ + ‘25’ as input data to iminyaka engama-25 as outputted text. That process might be done in line with Ariel Gutman’s realiser pipeline for Abstract Wikipedia and his proof-of-concept implementation with Scribunto or any other realizer architecture or system, such as Grammatical Framework, SimpleNLG, Ninai–Udiron, or Zola’s Nguni Grammar Engine, among several options for multilingual text generation. It might sound silly to put templates on top of the heavy machinery of a grammar engine, but it will make it more accessible to the general public so that they can specify how sentences should be generated. And, hopefully, permit a rules-as-you-go approach as well.
It is then the realiser (including grammar) engine and the partially or compulsorily attached computational grammar rules and other algorithms that work with the template. For the example, when it sees root and that the lemma fetched is a noun (L686326 is unyaka ‘year’), it also fetches the value of the noun class (a grammatical feature stored with the noun), which we always need somewhere for isiZulu NLG. It then needs to figure out to make a plural out of ‘year’, which it will know that it must do thanks to the years fetched for the instance (i.e., 25, which is plural) and the nummod that links to the root by virtue of the design and the assumption there’s a (dependency) grammar. Then, with concord:RelativeConcord, it will fetch the relative concord for that noun class, since concord also links to root. We already can do the concordial agreements and pluralising of nouns (and much more!) for isiZulu since several years. The only hurdle is that that code would need to become interoperable with the template language specification, in that our realisers will have to be able to recognise and process properly those ‘keywords’. Those words are part of an extensible set of words inspired by dependency grammars.
How this is supposed to interact smoothly is to be figured out still. Part of that is touched upon in the section about instrumentalising the template language: you could, for instance, specify it as functions in Wikifunctions that is instantly editable, facilitating an add-rules-as-you-go approach. Or it can be done less flexibly, by mapping or transforming it to another template language or to the specification of an external realiser (since it’s the principle of attachment, not embedding, of computational grammar rules).
In closing, whether the term “grammar-infused templates” will stick remains to be seen, but combining templates with grammars in some way for NLG will have a solid future at least for as long as those ML/DL-based large language model systems keep hallucinating and don’t consider languages other than English, including the intended multilingual setting for Abstract Wikipedia.
[3] Keet, C.M. Xakaza, M., Khumalo, L. Verbalising OWL ontologies in isiZulu with Python. The Semantic Web: ESWC 2017 Satellite Events, Blomqvist, E et al. (eds.). Springer LNCS vol 10577, 59-64. Portoroz, Slovenia, May 28 – June 2, 2017.
[6] Mahlaza, Z. Foundations for reusable and maintainable surface realisers for isiXhosa and isiZulu. PhD Thesis, Department of Computer Science, University of Cape Town, South Africa. 2022.
That last step in the process of generating text from some structured representation of data, information or knowledge is done by things called surface realizers. They take care of the ‘finishing touches’ – syntax, morphology, and orthography – to make good natural language sentences out of an ontology, conceptual data model, or Wikidata data, among many possible sources that can be used for declaring abstract representations. Besides theories, there are also many tools that try to get that working at least to some extent. Which ways, or system architectures, are available for generating the text? Which components do they all, or at least most of them, have? Where are the differences and how do they matter? Will they work for African languages? And if not, then what?
My soon-to-graduate PhD student Zola Mahlaza and I set out to answer these questions, and more, and the outcome is described in the article Surface realization architecture for low-resourced African languages that was recently accepted and is now in print with the ACM Transactions on Asian and Low-Resource Language Information Processing(ACM TALLIP) journal [1].
Zola examined 77 systems, which exhibited some 13 different principal architectures that could be classified into 6 distinct architecture categories. Purely by number of systems, manually coded and rule-based would be the most popular, but there are a few hybrid and data-driven systems as well. A consensus architecture for realisers there is not. And none exhibit most of the software maintainability characteristics, like modularity, reusability, and analysability that we need for African languages (even more so than for better resourced languages). African is narrowed down in the paper further to those in the Niger-Congo B (‘Bantu’) family of languages. One of the tricky things is that there’s a lot going on at the sub-word level with these languages, whereas practically all extant realizers operate at the word-level.
Hence, the next step was to create a new surface realizer architecture that is suitable for low-resourced African languages and that is maintainable. Perhaps unsurprisingly, since the paper is in print, this new architecture compares favourably against the required features. The new architecture also has ‘bonus’ features, like being guided by an ontology with a template ontology [2] for verification and interoperability. All its components and the rationale for putting it together this way are described in Section 5 of the article and the maintainability claims are discussed in its Section 6.
Source: [1]
There’s also a brief illustration how one can redesign a realiser into the proposed architecture. We redesigned the architecture of OWLSIZ for question generation in isiZulu [3] as use case. The code of that redesign of OWLSIZ is available, i.e., it’s not merely a case of just having drawn a different diagram, but it was actually proof-of-concept tested that it can be done.
While I obviously know what’s going on in the article, if you’d like to know much more details than what’s described there, I suggest you consult Zola as the main author of the article or his (soon to be available online) PhD thesis [4] that devotes roughly a chapter to this topic.
[4] Mahlaza, Z. Foundations for reusable and maintainable surface realisers for isiXhosa and isiZulu. PhD Thesis, Department of Computer Science, University of Cape Town, South Africa. 2022.
Natural language generation applications have been ‘mainstreaming’ behind the scenes for the last couple of years, from automatically generating text for images, to weather forecasts, summarising news articles, digital assistants that mechanically blurt out text based the structured information they have, and many more. Google, Reuters, BBC, Facebook – they all do it. Wikipedia is working on it as well, principally within the scope of Abstract Wikipedia to try to build a better multilingual Wikipedia [1] to reach more readers better. They all have some source of structured content – like data fetched from a database or spreadsheet, information from, say, a UML class diagram, or knowledge from some knowledge graph or ontology – and a specification as to what the structure of the sentence should be, typically with some grammar rules to at least prettify it, if not also being essential to generate a grammatically correct sentence [2]. That specification is written in templates that are then filled with content.
For instance, a simple rendering of a template may be “Each [C1] [R1] at least one [C2]” or “[I1] is an instance of [C1]”, where the things within the square brackets are variables standing in for content that will be fetched from the source, like a class, relationship, or individual. Linking these to a knowledge graph about universities, it may generate, e.g., “Each academic teaches at least one course” and “Joanne Soap is an instance of Academic”. To get the computer to do this, just “Each [C1] [R1] at least one [C2]” for template won’t do: we need to tell it what the components are so that the program can process it to generate that (pseudo-)natural language sentence.
Many years ago, we did this for multiple languages and used XML to specify the templates for the key aspects of the content. The structured input were conceptual data models in ORM in the DOGMA tool that had that verbalisation component [3]. As example, the template for verbalising a mandatory constraint was as follows:
Besides demarcating the sentence and indicating the constraint, there’s fixed text within the <text> … </text> tags and there’s the variable part with the <Object… that declares that the name of the object type has to be fetched and the <Role… that declares that the name of the relationship has to be fetched from the model (well, more precisely in this care: the reading label), which were elements declared in an XML Schema. With the same example as before, where Academic is in the object index “0” position and Course in the “1” position (see [3] for details), the software would then generate “ – [Mandatory] Each Academic must teaches at least one Course.”
This can be turned up several notches by adding grammatical features to it in order to handle, among others, gender for nouns in German, because they affect the rendering of the ‘each’ and ‘one’ in the sample sentence, not to mention the noun classes of isiZulu and many other languages [4], where even the verb conjugation depends on the noun class of the noun that plays the role of subject in the sentence. Or you could add sentence aggregation to combine two templates into one larger one to generate more flowy text, like a “Joanne Soap is an academic who teaches at least one course”. Or change the application scenario or the machinery for how to deal with the templates. For instance, instead of those variables in the template + code elsewhere that does the content fetching and any linguistic processing, we could put part of that in the template specification. Then there are no variables as such in the template, but functions. The template specification for that same constraint in an ORM diagram might then look like this:
ConstraintIsMandatory {
“[Mandatory] Each ”
FetchObjectType(0)
“ must ”
MakeInfinitive(FetchRole(0))
“ at least one ”
FetchObjectType(1)}
If you want to go with newer technology than markup languages, you may prefer to specify it in JSON. If you’re excited about functional programming languages and see everything through the lens of functions, you even can turn the whole template specification into a bunch of only functions. Either way: there must be a specification of how those templates are permitted to look like, or: what elements can be used to make a valid specification of a template. This so that the software will work properly so that it neither will spit out garbage nor will halt halfway before returning anything. What is permitted in a template language can be specified by means of a model, such as an XML Schema or a DTD, a JSON artefact, or even an ontology [5], a formal definition in some notation of choice, or by defining a grammar (be it a CFG or in BNF notation), and anyhow with enough documentation to figure out what’s going on.
How might this look like in the context of Abstract Wikipedia? For the natural language generation aspects and its first proposal for the realiser architecture, the structured content to be rendered in a natural language sentence is fetched from Wikidata, as is the lexicographic data, and the functions to do the various computations are to come from/go in Wikifunctions. They’re then combined with the templates in various stages in the realiser pipeline to generate those sentences. But there was still a gap as to what those templates in this context may look like. Ariel Gutman, a google.org fellow working on Abstract Wikipedia, and I gave it a try and that proposal for a template language for Abstract Wikipedia is now online accessible for comment, feedback, and, if you happen to speak a grammatically rich language, an option to provide difficult examples so that we can check whether the language is expressive enough.
The proposal is – as any other proposal for a software system – some combination of theoretical foundations, software infrastructure peculiarities, reasoned and arbitrary design decisions, compromises, and time constraints. Here’s a diagram of the key aspects of the syntax, i.e., with the elements, how they relate, and the constraints holding between them, in ORM notation:
An illustrative diagram with the key features of the template language in ORM notation.
There’s also a version in CFG notation, and there are a few examples, each of which shows how the template looks like for verbalising one piece of information (Malala Yousafzai’s age) in Swedish, French, Hebrew, and isiZulu. Swedish is the simplest one, as would English or Dutch be, so let’s begin with that:
Persoon_leeftijd_nl(Entity,Age_in_years): “{Person(Entity) is
{Age_in_years} jaar.}”
Where the Person(Entity) fetches the name of the person (that’s identified by an identifier) and the Age_in_years fetches the age. One may like to complicate matters and add a conditional statement, like that any age less than 30 will render that last part not just as jaar ‘year’, but as jaar oud ‘years old’ but jaar jong ‘years young’, but where that dividing line is, is a sensitive topic for some and I will let that rest. In any case, in Dutch, there’s no processing of the number itself to be able to render it in the sentence – 25 renders as 25 – but in other languages there is. For instance, in isiZulu. In that case, instead of a simple fetching of the number, we can put a function in the slot:
Where Lexeme(L686326) is the word for ‘year’ in isiZulu, unyaka, and for the rest, it first links the age rendering to the ‘year’ with the RelativeConcord() of that word, which practically fetches e- for the ‘years’ (iminyaka, noun class 4), then gets the copulative (ng in this case), and then the concord for the noun class of the noun of the number. Malala is in her 20s, which is amashumi amabili .. (noun class 6, which is computed via Cardinal(years)), and thus the function nounPrefix will fetch ama-. So, for Malala’s age data, Year_zu(years) will return iminyaka engama-25. That then gets processed with the rest of the Person_AgeYr_zu template, such as adding an U to the name by subj:Person(Entity), and later steps in the pipeline that take care of things like phonological conditioning (-na- + i- = –ne-), to eventually output UMalala Yousafzai uneminyaka engama-25. In other words: such a template indeed can be specified with the proposed template syntax.
There’s also a section in the proposal about how that template language then connects to the composition syntax so that it can be processed by the Wikifunctions Orchestrator component of the overall architecture. That helps hiding a few complexities from the template declarations, but, yes, someone’s got to write those functions (or take them from existing grammar engines) that will take care of those more or less complicated processing steps. That’s a different problem to solve. You also could link it up with another realiser by means of a transformation the the input type it expects. For now, it’s the syntax of the declarative part for the templates.
If you have any questions or comments or suggestions on that proposal or interesting use cases to test with, please don’t hesitate to add something to the talk page of the proposal, leave a comment here, or contact either Ariel or me directly.
[5] Mahlaza, Z., Keet, C. M. ToCT: A Task Ontology to Manage Complex Templates. Proceedings of the Joint Ontology Workshops 2021, FOIS’21 Ontology Showcase. Sanfilippo, E.M. et al. (Eds.). CEUR-WS vol. 2969. 9p.
I’m aware that to most people ‘playing with’ (investigating) ontologies and isiZulu does not sound particularly useful on the face of it. Yet, there’s the some long-term future music, like eventually being able to generate patient discharge notes in one’s own language, which will do its bit to ameliorate the language barrier in healthcare in South Africa so that patients at least will adhere to the treatment instructions a little better, and therewith receive better quality healthcare. But benefits in the short-term might serve something as well. To that end, I proposed an honours project last year, which has been completed in the meantime, and one of the two interesting outcomes has made it into a publication already [1]. As you may have guessed from the title, it’s about automation for language learning exercises. The results will be presented at the 6th Workshop on Controlled Natural Language, in Maynooth, Ireland in about 2 weeks time (27-28 August). In the remainder of this post, I highlight the main contributions described in the paper.
First, regarding the post’s title, one might wonder what ontology verbalisation has to do with language learning. Nothing, really, except that we could reuse the algorithms from the controlled natural language (CNL) for ontology verbalisation to generate (computer-assisted) language learning exercises whose answers can be computed and marked automatically. That is, the original design of the CNL for things like pluralising nouns, verb conjugation, and negation that is used for verbalising ontologies in isiZulu in theory [2] and in practice [3], was such that the sentence generator is a detachable module that could be plugged in elsewhere for another task that needs such operations.
Practically, the student who designed and developed the back-end, Nikhil Gilbert, preferred Java over Python, so he converted most parts into Java, and added a bit more, notably the ‘singulariser’, a sentence scrabble, and a sentence generator. Regarding the sentence generator, this is used as part of the exercises & answers generator. For instance, we know that humans and the roles they play (father, aunt, doctor, etc.) are mostly in isiZulu’s noun classes 1, 2, 1a, 2a, or 3a, that those classes do not (or rarely?) have non-human nouns and generally it holds for all humans and their roles that they can ‘eat’, ‘talk’ etc. This makes it relatively easy create a noun chain and a verb chain list to mix and match nouns with verbs accordingly (hurrah! for the semantics-based noun class system). Then, with the 231 nouns and 59 verbs in the newly constructed mini-corpus, the noun chain and the verb chain, 39501 unique question sentences could be generated, using the following overall architecture of the system:
Architecture of the CNL-driven CALL system. The arrows indicate which upper layer components make use of the lower layer components. (Source: [1])
From a CNL perspective as well as the language learning perspective, the actual templates for the exercises may be of interest. For instance, when a learner is learning about pluralising nouns and their associated verb, the system uses the following two templates for the questions and answers:
The answers can be generated automatically with the algorithms that generate the plural noun (from ‘prefixSG’ to ‘prefixPL’) and add the plural subject concord (from ‘SGSC’ to ‘PLSC’, in agreement with ‘prefixPL’), which were developed as part of the GeNI project on ontology verbalization. This can then be checked against what the learner has typed. For instance, a generated question could be umfowethu usula inkomishi and the correct answer generated (to check the learner’s response against) is abafowethu basula izinkomishi. Another example is generation of the negation from the positive, or, vv.; e.g.:
Q: <PLSC+VerbRoot+FV>
A: <PLNEGSC+VerbRoot+NEGFV>
For instance, the question may present batotoba and the correct answer is then abatotobi. In total, there are six different types of sentences, with two double, like the plural above, hence a total of 16 templates. It is not a lot, but it turned out it is one of the very few attempts to use a CNL in such way: there is one paper that also will be presented at CNL’18 in the same session [4], and an earlier one [5] uses a fancy grammar system (that we don’t have yet computationally for isiZulu). This is not to be misunderstood as that this is one of the first CNL/NLG-based system for computer-assisted language learning—e.g., there’s assistance in essay writing, grammar concept question generation, reading understanding question generation—but curiously very little on CNLs or NLG for the standard entry-level type of questions to learn the grammar. Perhaps the latter is considered ‘boring’ for English by now, given all the resources. However, thousands of students take introduction courses in isiZulu each year, and some automation can alleviate the pressure of routine activities from the lecturers. We have done some evaluations with learners—with encouraging results—and plan to do some more, so that it may eventually transition to actual use in the courses; that is: TBC…
[3] Keet, C.M. Xakaza, M., Khumalo, L. Verbalising OWL ontologies in isiZulu with Python. The Semantic Web: ESWC 2017 Satellite Events, Blomqvist, E. et al. (eds.). Springer LNCS vol. 10577, 59-64.
[4] Lange, H., Ljunglof, P. Putting control into language learning. 6th International Workshop on Controlled Natural language (CNL’18). IOS Press. Co. Kildare, Ireland, 27-28 August 2018. (in print)
If you have read any of the blog posts on (automated) natural language generation for isiZulu, then you’ll probably agree with me that isiZulu verbs are non-trivial. True, verbs in other languages are most likely not as easy as in English, or Afrikaans for that matter (e.g., they made irregular verbs regular), but there are many little ‘bits and pieces’ ‘glued’ onto the verb root that make it semantically a ‘heavy’ element in a sentence. For instance:
Aba-shana ba-ya-zi-theng-is-el-an-a izimpahla
Children 2.SC-Pres-8.OC-buyVR -C-A-R-FV 8.clothes
‘The children are selling the clothes to each other’
The ba is the subject concord (~conjugation) to match with the noun class (which is 2) of the noun that plays the subject in the sentence (abashana), the ya denotes a continuous action (‘are doing something’ in the present), the zi is the object concord for the noun class (8) of the noun that plays the object in the sentence (izimpahla), theng is the verb root, then comes the CARP extension with is the causative (turning ‘buy’ into ‘sell’), and el the applicative and an the reciprocative, which take care of the ‘to each other’, and then finally the final vowel a.
More precisely, the general basic structure of the verb is as follows:
where NEG is the negative; SC the subject concord; T/A denotes tense/aspect; MOD the mood; OC the object concord; Verb Rad the verb radical; C the causative; A the applicative; R the reciprocal; and P the passive. For instance, if the children were not selling the clothes to each other, then instead of the SC, there would be the NEG SC in that position, making the verb abayazithengiselana.
To make sense of all this in a way that it would be amenable to computation, we—my co-author Langa Khumalo and I—specified the grammar of the complex verb for the present tense in a CFG using an incremental process of development. To the best of our (and the reviewer’s) knowledge, the outcome of the lengthy exercise is (1) the first comprehensive and precisely formulated documentation of the grammar rules for the isiZulu verb present tense, (2) all together in one place (cf. fragments sprinkled around in different papers, Wikipedia, and outdated literature (Doke in 1927 and 1935)), and (3) goes well beyond handling just one of the CARP, among others. The figure below summarises those rules, which are explained in detail in the forthcoming paper “Grammar rules for the isiZulu complex verb”, which will be published in the Southern African Linguistics and Applied Language Studies [1] (finally in print, yay!).
It is one thing to write these rules down on paper, and another to verify whether they’re actually doing what they’re supposed to be doing. Instead of fallible and laborious manual checking, we put them in JFLAP (for the lack of a better alternative at the time; discussed in the paper) and tested the CFG both on generation and recognition. The tests went reasonably well, and it helped fixing a rule during the testing phase.
Because the CFG doesn’t take into account phonological conditioning for the vowels, it generates strings not in the language. Such phonological conditioning is considered to be a post-processing step and was beyond the scope of elucidating and specifying the rules themselves. There are other causes of overgeneration that we did not get around to doing, for various reasons: there are rules that go across the verb root, which are simple to represent in coding-style notation (see paper) but not so much in a CFG, and rules for different types of verbs, but there’s no available resource that lists which verb roots are intransitive, which as monosyllabic and so on. We have started with scoping rules and solving issues for the latter, and do have a subset of phonological conditioning rules; so, to be continued… For now, though, we have completed at least one of the milestones.
Last, but not least, in case you wonder what’s the use of all this besides the linguistics to satisfy one’s curiosity and investigate and document an underresourced language: natural language generation for intelligent user interfaces in localised software, spellcheckers, and grammar checkers, among others.
References
[1] Keet, C.M., Khumalo, L. Grammar rules for the isiZulu complex verb. Southern African Linguistics and Applied Language Studies, (in print). Submitted version (the rules are the same as in the final version)
Earlier this week the 5th Workshop on Controlled Natural Language (CNL’16) was held in Aberdeen, Scotland, where I presented progress made on a Runyankore CNL [1], rather than my student, Joan Byamugisha, who did most of the work on it (she could not attend due to nasty immigration rules by the UK, not a funding issue).
“Runyankore?”, you might ask. It is one of the languages spoken in Uganda. As Runyankore is very under-resourced, any bootstrapping to take a ‘shortcut’ to develop language resources would be welcome. We have a CNL for isiZulu [2], but that is spoken in South Africa, which is a few thousand kilometres further south of Uganda, and it is in a different Guthrie zone of the—in linguistics still called—Bantu languages, so it was a bit of a gamble to see whether those results could be repurposed for Runynakore. They could, needing only minor changes.
What stayed the same were the variables, or: components to make up a grammatically correct sentence when generating a sentence within the context of OWL axioms (ALC, to be more precise). They are: the noun class of the name of the concept (each noun is assigned a noun class—there are 20 in Runyankore), the category of the concept (e.g., noun, adjective), whether the concept is atomic (named OWL class) or an OWL class expression, the quantifier used in the axiom, and the position of the concept in the axiom. The only two real differences were that for universal quantification the word for the quantifier is the same when in the singular (cf. isiZulu, where it changes for both singular or plural), and for disjointness there is only one word, ti ‘is not’ (cf. isiZulu’s negative subject concord + pronomial). Two very minor differences are that for existential quantification ‘at least one’, the ‘at least’ is in a different place in the sentence but the ‘one’ behaves exactly the same, and ‘all’ for universal quantification comes after the head noun rather than before (but is also still dependent on the noun class).
It goes without saying that the vocabulary is different, but that is a minor aspect compared to figuring out the surface realisation for an axiom. Where the bootstrapping thus came in handy was that that arduous step of investigating from scratch the natural language grammar involved in verbalising OWL axioms could be skipped and instead the ones for isiZulu could be reused. Yay. This makes it look very promising to port to other languages in the Bantu language family. (yes, I know, “one swallow does not a summer make” [some Dutch proverb], but one surely is justified to turn up one’s hope a notch regarding generalizability and transferability of results.)
Joan also conducted a user survey to ascertain which surface realisation was preferred among Runyankore speakers, implemented the algorithms, and devised a new one for the ‘hasX’ naming scheme of OWL object properties (like hasSymptom and hasChild). All these details, as well as the details of the Runyankore CNL and the bootstrapping, are described in the paper [1].
I cannot resist a final comment on all this. There are people who like to pull it down and trivialise natural language interfaces for African languages, on the grounds of “who cares about text in those kind of countries; we have to accommodate the illiteracy with pictures and icons and speech and such”. People are not as illiterate as is claimed here and there (including by still mentally colonised people from African countries)—if they were, then the likes of Google and Facebook and Microsoft would not invest in localising their interfaces in African languages. The term “illiterate” is used by those people to include also those who do not read/write in English (typically an/the official language of government), even though they can read and write in their local language. People who can read and write—whichever natural language it may be—are not illiterate, neither here in Africa nor anywhere else. English is not the yardstick of (il)literacy, and anyone who thinks it is should think again and reflect a bit on cultural imperialism for starters.
Yes, Google Translate English-isiZulu does exist, but it has many errors (some very funny) and there’s a lot more to Natural Language Generation (NLG) than machine translation, such as natural language-based query interfaces that has some AI behind it, and they are needed, too [1]. Why should one bother with isiZulu? Muendane has his lucid opinions about that [2], and in addition to that, it is the first language of about 23% of the population of South Africa (amounting to some 10 million people), about half can speak it, and it is a Bantu language, which is spoken by nearly 300 million people—what works for isiZulu grammar may well be transferrable to its related languages. Moreover, it being in a different language family than the more well-resourced languages, it can uncover some new problems to solve for NLG, and facilitate access to online information without the hurdle of having to learn English or French first, as is the case now in Sub-Saharan Africa.
The three principal approaches for NLG are canned text, templates, and grammars. While I knew from previous efforts [3] that the template-based approach is very well doable but has its limitations, and knowing some basic isiZulu, I guessed it might not work with the template-based approach but appealing if it would (for a range of reasons), that no single template could be identified so far was the other end of the spectrum. Put differently: we had to make a start with something resembling the foundations of a grammar engine.
Langa Khumalo, with the Linguistics program and director of the University Language Planning and Development Office at the University of KwaZulu-Natal, and I have been trying to come up with isiZulu NLG. We have patterns and algorithms for (‘simple’) universal and existential quantification, subsumption, negation (class disjointness), and conjunction; or: roughly OWL 2 EL and a restricted version of ALC. OWL 2 EL fist neatly with SNOMED CT, and therewith has the potential for interactive healthcare applications with the isiZulu healthcare terminologies that are being developed at UKZN.
The first results on isiZulu NLG are described in [4,5], which was not an act of salami-slicing, but we had more results than that fitted in a single paper. The first paper [4] will appear in the proceedings ofthe 4th workshop on Controlled Natural language (CNL’14), and is about finding those patterns and, for the options available, an attempt at figuring out which one would be best. The second paper [5], which will appear in the 8th International Web Rule Symposium (RuleML’14) conference proceedings, is more about devising the algorithms to make it work and how to actually generate those sentences. Langa and I plan to attend both events, so you can ask us about the details either in Prague (18-20 Aug) or Galway (20-22 Aug) in person. In the meantime, the CRCs of the papers are online (here and here).
Regarding the technical aspects, the main reasons why we cannot get away with devising templates to generate isiZulu controlled natural language is that isiZulu is non-trivial:
There is a whole system of noun classes: nouns are grouped in one of the 17 noun classes, each with their own peculiarities, which is illustrated in Figure 1, below;
Agglutination, informally: putting lots of bits and pieces together to make a word. A selection of those so-called ‘concords’ is included in Figure 2, below;
Phonological conditioned copulatives, meaning that the ‘is a’ depends on the term that comes after it (ng or y); and
Complex verb conjugation.
isiZulu noun classes with an example (source: [5]).
A selection of isiZulu concords (source: [5])
What does this mean for the verbalization? In English, we use ‘Each…’ or ‘For all…’ for the universal quantifier and it doesn’t matter over which noun it is quantified. In isiZulu, it does. Each noun class has its own ‘each’ and ‘for all’, and it is not acceptable (understandable) to use one for the wrong noun class. For disjointness, like “Cup is not a Glass” ( in DL), in English we have the ‘is not a’ regardless what comes before or after the subsumption+negation, but in isiZulu, the copulative is omitted, the first noun (OWL class, if you will) brings in a so-called negative subject concord, the second noun brings in a pronominal, and they are glued together (e.g., Indebe akuyona Ingilazi, where the second word is composed of aku + yona), and to top it off, each noun class has its own concord and pronomial. A seemingly simple conjunction—just an ‘and’ in English—has to be divided into an and-when-it-is-used-in-an-enumeration and an and-when-it-is-a-connective, and when it is used in an enumeration, it depends on the first letter of the noun that comes after the ‘and’. Existential quantification is even more of a hassle. The table below shows a very brief summary comparing typical patterns in English with those for isiZulu.
A few DL symbols, their typical verbalization options in English, and an indication of possible patterns (source: [4])
We did ask isiZulu speakers which of the possible options they preferred (in a survey, with Limesurvey localized to isiZulu), but there wasn’t an overwhelming consistent agreement among them except for one of the options for existential quantification (the –dwa option), although there was more agreement among the linguists than among the non-linguists, possibly due to dialect influences (results can be found in [4]).
If you don’t feel like reading the two papers, but still would like to have some general overview and examples, you also can check out the slides of the CS colloquium I gave last week. I managed to ‘lure in’ also ICT4D people—and then smack them with a bit of logic and algorithms—but the other option, being talking about the other paper accepted at RuleML, probably would have had to be a ‘cookie colloquium’ to get anyone to attend (more about that paper in another post—it is fascinating, but possibly of less interest to a broader audience). If you want to skip the tedious bits and just get a feel of how one of the algorithms works out: check out the example starting on slide 63, which shows the steps to go from in FOL, or in DL (“Each professor teaches at least one course”, if the vocabulary were in English), to “Bonke oSolwazi bafundisa isifundo esisodwa”.
[4] Keet, C.M., Khumalo, L. Toward verbalizing logical theories in isiZulu. 4th Workshop on Controlled Natural Language (CNL’14), 20-22 August 2014, Galway, Ireland. Springer LNAI. (in press)















![isiZulu noun classes with an example (source: [5]).](https://keet.wordpress.com/wp-content/uploads/2014/06/ncexamples.png)
![A selection of isiZulu concords (source: [5])](https://keet.wordpress.com/wp-content/uploads/2014/06/concordsselection.png)
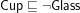 in DL), in English we have the ‘is not a’ regardless what comes before or after the subsumption+negation, but in isiZulu, the copulative is omitted, the first noun (OWL class, if you will) brings in a so-called negative subject concord, the second noun brings in a pronominal, and they are glued together (e.g., Indebe akuyona Ingilazi, where the second word is composed of aku + yona), and to top it off, each noun class has its own concord and pronomial. A seemingly simple conjunction—just an ‘and’ in English—has to be divided into an and-when-it-is-used-in-an-enumeration and an and-when-it-is-a-connective, and when it is used in an enumeration, it depends on the first letter of the noun that comes after the ‘and’. Existential quantification is even more of a hassle. The table below shows a very brief summary comparing typical patterns in English with those for isiZulu.
in DL), in English we have the ‘is not a’ regardless what comes before or after the subsumption+negation, but in isiZulu, the copulative is omitted, the first noun (OWL class, if you will) brings in a so-called negative subject concord, the second noun brings in a pronominal, and they are glued together (e.g., Indebe akuyona Ingilazi, where the second word is composed of aku + yona), and to top it off, each noun class has its own concord and pronomial. A seemingly simple conjunction—just an ‘and’ in English—has to be divided into an and-when-it-is-used-in-an-enumeration and an and-when-it-is-a-connective, and when it is used in an enumeration, it depends on the first letter of the noun that comes after the ‘and’. Existential quantification is even more of a hassle. The table below shows a very brief summary comparing typical patterns in English with those for isiZulu.
![A few DL symbols, their typical verbalization options in English, and an indication of possible patterns (source: [4])](https://keet.wordpress.com/wp-content/uploads/2014/06/zuluconsoptions.png)
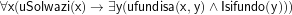 in FOL, or
in FOL, or  in DL (“Each professor teaches at least one course”, if the vocabulary were in English), to “Bonke oSolwazi bafundisa isifundo esisodwa”.
in DL (“Each professor teaches at least one course”, if the vocabulary were in English), to “Bonke oSolwazi bafundisa isifundo esisodwa”.