
It was published last month by Springer: “The what and how of modelling information and knowledge: from mind maps to ontologies”. The book’s three character-limited unique selling points are that it “introduces models and modelling processes to improve analytical skills and precision; describes and compares five modelling approaches: mind maps, models in biology, conceptual data models, ontologies, and ontology; aims at readers looking for a digestible introduction to information modelling and knowledge representation”. The softcover hardcopy and the eBook are available from Springer, Springer professional, many national and international online retailers (e.g., Amazon), as well as university libraries, and hopefully soon in the ‘science’ section of select bookstores.
There’s also a back flap blurb with the book’s motivations and aims, and intended readership. The remainder of this post are informal comments on it.
From my side as author and having read many popular science books on a wide range of topics, I wanted to write a popular science book too, but then about modelling. Modelling for the masses, as it were, or at least something that is comparatively easily readable for professionals who don’t have a computing background and who haven’t had, or had very little, training in modelling, yet who can greatly benefit from doing so. And to some extent also for computing and IT professionals who’d like a refresher on information modelling or a concise introduction to ontologies but don’t want to (re-)open their textbook tomes from college. Modelling doesn’t lend itself well to juicy world-changing discoveries the same way that vaccines and fungi can be themes for page-turners, but a few tales and juicy details do exist.
Then next consideration was about which aspects of modelling to include and what sort of popular science book to aim for. I distinguished four types of popular science books based on my prior readings, ranging from ‘entertaining layperson’ level holiday reading to ‘advanced interested layperson’ level where having at least a Bachelors in that field or a Master’s degree in an adjacent field may be needed to make it through the tiny-font book. I have no experience writing humour, and modelling is a rather dry topic compared to laugh-out-loud musings and investigations into stupidity, drunkenness, or elephants on acid—that entertainment can be found here, here, and here—so that was easily excluded. I’ve already tried out advanced texts tailored to specialists, in the form of an award-winning postgraduate textbook on ontology engineering, and wasn’t in the mood for writing another such book at the time when I was exploring ideas, which was around late 2021 and early 2022. I think this modelling book ended up between the two extremes regarding the amount of content, difficulty, and readability.
And so, I chose the tone of writing to be in so-called ‘casual writing’ style to make it more readable, there are a few anecdotes to enliven the text as is customary for popular science books, and the first three chapters are relatively easy in content compared to later chapters. The difficulty level of the chapters’ contents is turned up a notch each chapter going from Chapters 2 to 6 when we’re moving onwards with the journey passing by the five types of models covered in the book. Each successive chapter solves modelling limitations from the preceding chapter, and so it gets more challenging at least up to Chapter 5 (ontologies). Whether a reader finds Chapter 6 on Ontology (philosophy) even harder, depends on their background, because in other ways it is easier than ontologies because we can set aside certain interfering practicalities.
Chapter 7 mixes easier use cases with theoretically more abstract sections when we’re putting things together, reflect on Chapters 2-6, and look ahead. There’s no avoiding a little challenge. But then, we read non-fiction/science/tech books to learn from it and learning requires some effort.
Aside from the reader learning from reading the book, an author is supposed to gain new insights from writing it. And so did I. Moreover, upfront when planning the book, I tried to make sure I likely would. I mention a few salient points in the preface and I’ll select two for this blog post: the cladograms (Section 3.2.1) and the task-based evaluation (Section 7.1.2.2).
Diagrams/models in biology are sometimes ridiculed as “cartoons” by non-biologists. Cladograms would be the xkcd version of it, visually. I already knew that there are common practices, recurring icons, and rules governing the biological models drawn as diagrams. Digging deeper to find more diagrams with rules governing their notation, cladograms came up. They visualise key aspects of the scientific theory of evolution. Conversely, drawing an evolutionary diagram that doesn’t adhere to those rules then amounts to misunderstanding evolution. I think the case deserves more attention, especially because a bunch of school textbooks have been shown to have errors, and there’s room for improvement designing cladogram drawing software. Maybe clarifying matters and being more precise with such models helps resolve some debates on the topic as well.
The motivation for the task-based evaluation is easy to argue for in theory — actually doing it offered a deeper understanding, and writing the book spurred me to do so. One of my claims in the beginning of the book is that with better modelling—better than mind maps, not better mind maps—one learns more. The task-based evaluation is precisely about that. We take one page from a textbook and try to create a model of it, one for each type of model covered in the book. It demonstrates in a clear and straightforward way — assisted by Bloom’s taxonomy if you so fancy — why developing an ontology is much harder than developing a mind map or a conceptual data model, and in what way designing a conceptual data model of that textbook page is better for learning the content than creating a mind map of it.
There were more joys of writing the book. Like that the running example—dance—was also good for some additional interesting paper reading beyond what I already had read and engaged with in various projects. (There are also other subject domains in the examples and illustrations, such as fermentation, peace, labour law, and stuff, and a separate post will be dedicated to more content of the book.)
To jump the gun on questions like “why didn’t you include my preferred type of model or my language, being [DSL x/KG y/BPM z/etc.]?”: the point I wanted to make with this book was made with these five types of models and this was the shortest coherent story arc with which I could do it. The DSLs/KGs/BPMs/etc are not less worthy, but they would have caused the number of pages to explode without adding to the argument. As consolation, perhaps: knowledge graphs (KGs) are likely to appear in a v2 of my ontology engineering textbook and BPM likely will be linked to the TREND temporal conceptual data modelling language, but that’s future music.
Last, I’ve created a web page for the book, which collates information about the book, such as direct links where to buy it, media coverage and links to recent related blog posts (e.g., this one is a spin-off [with an add-on] of an early draft of section 6.3 and that one of a draft of section 7.3), and has extra supplementary material, including a longer illustration of a conceptual model design procedure using a prospective dance school database as example. Feedback is welcome!



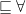






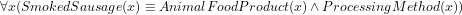 (which is ontologically incorrect because a smoked sausage is not way of processing) or, if done with a ‘cross-product’ and a new relation (
(which is ontologically incorrect because a smoked sausage is not way of processing) or, if done with a ‘cross-product’ and a new relation ( ), then the resulting computation will have something alike
), then the resulting computation will have something alike  instead of having declared directly in the ontology proper, say,
instead of having declared directly in the ontology proper, say, 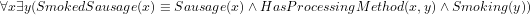 . The latter option has the advantages that it makes it easier to add, say, Fermented smoked sausage or Cooked smoked sausage as a sausage that has the two properties of being [fermented/cooked] and being smoked, and that one can avail of automated reasoners to classify the taxonomy. Either way, the details are being worked on. The ontology language and the choice for one or the other—whichever it may be—ought not to get in the way of developing an ontology, but, generally, it does so both regarding underlying commitment that the language adheres to and any implicit or explicit workaround in the modelling stage that to some extent make up for a language’s limitations.
. The latter option has the advantages that it makes it easier to add, say, Fermented smoked sausage or Cooked smoked sausage as a sausage that has the two properties of being [fermented/cooked] and being smoked, and that one can avail of automated reasoners to classify the taxonomy. Either way, the details are being worked on. The ontology language and the choice for one or the other—whichever it may be—ought not to get in the way of developing an ontology, but, generally, it does so both regarding underlying commitment that the language adheres to and any implicit or explicit workaround in the modelling stage that to some extent make up for a language’s limitations.

