From the “10 years of keetblog – reblogging: 2006”: a preliminary post that led to the OWLED 2007 paper I co-authored with Marco Roos and Scott Marshall, when I was still predominantly into bio-ontologies and biological databases. The paper received quite a few citations, and a good ‘harvest’ from both OWLED’07 and co-located DL’07 participants on how those requirements may be met (described here). The original post: Figuring out requirements for automated reasoning services for formal bio-ontologies, from Dec 27, 2006.
What does the user want? There is a whole sub-discipline on requirements engineering, where researchers look into methodologies how one best can extract the users’ desires for a software application and organize the requirements according to type and priority. But what to do when users – in this case biologists and (mostly non-formal) bio-ontologies developers – neither do know clearly themselves what they want nor what type of automated reasoning is already ‘on offer’. Here, I’m making a start by briefly listing informally some of the desires & usages that I came across in the literature, picked up from conversations and further probing to disambiguate the (for a logician) vague descriptions, or bumped into myself; they are summarised at the end of this blog entry and update (d.d. 5-5-’07) described more comprehensively in [0].
Feel free to add your wishes & demands; it may even be fed back into current research like [1] or be supported already after all. (An alternative approach is describing ‘scenarios’ from which one can try to extract the required reasoning tasks; if you want to, you can add those as well.)
I. A fairly obvious use of automated reasoners such as Racer, Pellet and FaCT++ with ontologies is to let the software find errors (inconsistencies) in the representation of the knowledge or reality. This is particularly useful to ensure no ‘contradictory’ information remains in the ontology when an ontology gets too big for one person to comprehend and multiple people update an ontology. Also, it tends to facilitate learning how to formally represent something. Hence, the usage is to support the ontology development process.
But this is just the beginning: having a formal ontology gives you other nice options, or at least that is the dangling carrot on front of the developer’s nose.
II. One demonstration of the advantages of having a formal ontology, thus not merely a promise, is the classification of protein phosphatases by Wolstencroft et al. [9], where also some modest results were obtained in discovering novel information about those phosphatases that was entailed in the extant information but hitherto unknown. Bandini and Mosca [2] pushed a closely related idea one step further in another direction. To constrain the search space of candidate rubber molecules for tire production, they defined the constraints (properties) all types of molecules for tires must satisfy in the TBox, treated each candidate molecule as an instance in the ABox, and performed model checking on the knowledgebase: each instance inconsistent w.r.t. the TBox was thrown out of the pool of candidate-molecules. Overall, the formal representation with model checking achieved a considerable reduction in resource usage of the system and reduced the amount of costly wet-lab research. Hence, the usages are classification and model checking.[i]
III. Whereas the former includes usage of particular instances for the reasoning scenarios, another on is to stay at the type level and, in particular, relations between the types (classes in the class hierarchy in Protégé). In short, some users want to discover new or missing relations. What type of relation is not always exactly clear, but I assume for now that any non-isA relation would do. For instance, Roos et al. [8] would like to do that for the subject domain of histones; with or without instance-level data. The former, using instance-level data, resembles the reverse engineering option in VisioModeler, which takes a physical database schema and the data stored in the tables and computes the likely entities, relations, and constraints at the level of a conceptual model (in casu, ORM). Mungall [7] wants to “Check for inconsistent or missing relationships” and “Automatically assign relationships for new terms”. How can one find what is not there but ought to be in the ontology? An automated reasoner is not an oracle. I will split up this topic into two aspects. First, one can derive relations among types, meaning that some ontology developer has declared several types, relations, other properties, but not everything. The reasoner then, takes the declared knowledge and can return relations that are logically implied by the formal ontology. From a user perspective, such a derived relation may be perceived as a ‘new’ or ‘missing’ relation – but it did not fall out of the sky because the relation was already entailed in the ontology (or: you did not realize you knew it already). Second, another notion of ‘missing relations’: e.g. there are 17 types of macrophages (types of cell) in the FMA, which must be part of, contained in, or located in something. If you query the FMA through OQAFMA, it gives as answer that the hepatic macrophage is part of the liver [5]. An informed user knows it cannot be the case that the other macrophages are not part of anything. Then, the ontology developer may want to fill this gap – adding the ‘missing’ relations – by further developing those cell-level sections of the ontology. Note that the reasoner will not second-guess you by asking “do you want more things there?”; it uses the Open World Assumption, i.e. that there always may be more than actually represented on the ontology (and absence of some piece of information is not negation of that piece). Thus, the requirements are to have some way of dealing with `gaps’ in an ontology, to support computing derived relations entailed in a logical theory, and, third, deriving type-level relations based on instance-level data. The second one is already supported, the first one only with intervention by an informed user, and the third one might, to some extent.
Now three shorter points, either because there is even less material or there is too much to stuff it in this blog entry.
IV. A ‘this would be nice’ suggestion from Christina Hettne, among others, concerns the desire to compare pathways, which, in its simplest form, amounts to checking for sub-graph isomorphisms. More generally, one could – or should be able to – treat an ontology as a scientific theory [6] and compare competing explanations of some natural phenomenon (provided both are represented formally). Thus, we have a requirement for comparison of two ontologies, not with the aim of doing meaning negotiation and/or merging them, but where the discrepancies themselves are the fun part. This indicates that dealing with ‘errors’ that a reasoner spits out could use an upgrade toward user-friendliness.
V. Reasoning with parthood and parthood-like relations in bio-ontologies are on a par with importance of the subsumption relation. Donnelly [3] and Keet [4], among many, would like to use parthood and parthood-like relations for reasoning, covering more than transitivity alone. Generalizing a bit, we have another requirement: reasoning with properties (relations) and hierarchies of relations, focusing first on the part-whole relation. What reasoning services are required exactly, be it for parthood or any other relation, deserves an entry on its own.
VI. And whatnot? For instance, linking up different ontologies that each reside at their own level of granularity, yet have enabled to perform ‘granular cross-ontology queries’, or infer locations of diseases based on combining an anatomy ontology with a disease taxonomy, hence, reasoning over linked ontologies. This needs to be written down in more detail, and may be covered at least partially with point two in item III.
Summarizing, we have to following requirements for automated reasoning services, in random order w.r.t. importance:
- Support in the ontology development process;
- Classification;
- Model checking;
- Finding ‘gaps’ in the content of an ontology;
- Computing derived relations at the type level;
- Deriving type-level relations from instance-level data;
- Comparison of two ontologies ([logical] theories);
- Reasoning with a plethora of parthood and parthood-like relations;
- Using (including finding inconsistencies in) a hierarchy of relations in conjunction with the class hierarchy;
- Reasoning across linked ontologies;
I doubt this is an exhaustive list, and expect to add more requirements & desires soon. They also have to be specified more precisely than explained briefly above and the solutions to meet these requirements need to be elaborated upon as well.
[0] Keet, C.M., Roos, M., Marshall, M.S. A survey of requirements for automated reasoning services for bio-ontologies in OWL. Third international Workshop OWL: Experiences and Directions (OWLED 2007), 6-7 June 2007, Innsbruck, Austria. CEUR-WS.
[1] European FP6 FET Project “Thinking ONtologiES (TONES)”. (UDATE 29-7-2015: URL defunct by now)
[2] Bandini, S., Mosca, A. Mereological knowledge representation for the chemical formulation. 2nd Workshop on Formal Ontologies Meets Industry 2006 (FOMI2006), 14-15 December 2006, Trento, Italy. pp55-69.
[3] Donnelly, M., Bittner, T. and Rosse, C. A Formal Theory for Spatial Representation and Reasoning in Biomedical Ontologies. Artificial Intelligence in Medicine, 2006, 36(1):1-27.
[4] Keet, C.M. Part-whole relations in Object-Role Models. 2nd International Workshop on Object-Role Modelling (ORM 2006), Montpellier, France, Nov 2-3, 2006. In: OTM Workshops 2006. Meersman, R., Tari, Z., Herrero., P. et al. (Eds.), LNCS 4278. Berlin: Springer-Verlag, 2006. pp1116-1127.
[5] Keet, C.M. Granular information retrieval from the Gene Ontology and from the Foundational Model of Anatomy with OQAFMA. KRDB Research Centre Technical Report KRDB06-1, Free University of Bozen-Bolzano, 6 April 2006. 19p.
[6] Keet, C.M. Factors affecting ontology development in ecology. Data Integration in the Life Sciences 2005 (DILS2005), Ludaescher, B, Raschid, L. (eds.). San Diego, USA, 20-22 July 2005. Lecture Notes in Bioinformatics 3615, Springer Verlag, 2005. pp46-62.
[7] Mungall, C.J. Obol: integrating language and meaning in bio-ontologies. Comparative and Functional Genomics, 2004, 5(6-7):509-520. (UPDATE: link rot as well; a freely accessible veriosn is available at: http://berkeleybop.org/~cjm/obol/doc/Mungall_CFG_2004.pdf)
[8] Roos, M., Rauwerda, H., Marshall, M.S., Post, L., Inda, M., Henkel, C., Breit, T. Towards a virtual laboratory for integrative bioinformatics research. CSBio Reader: Extended abstracts of “CS & IT with/for Biology” Seminar Series 2005. Free University of Bozen-Bolzano, 2005. pp18-25.
[9] Wolstencroft, K., Lord, P., Tabernero, L., Brass, A., Stevens, R. Using ontology reasoning to classify protein phosphatases [abstract]. 8th Annual Bio-Ontologies Meeting; 2005 24 June; Detroit, United States of America.
[i] Observe another aspect regarding model checking where the automated reasoner checks if the theory is satisfiable, or: given your ontology, if there is/can be a combination of instances such that all the declared knowledge in the ontology holds (is true), which is called a `model’ (as well, like so many things). That an ontology is satisfiable does not imply it only has models as intended by you, i.e. there is a difference between ‘all models’ and ‘all intended models’. If an ontology is satisfiable it means that it is logically possible that each type can be instantiated without running into inconsistencies; it neither demonstrates that one can indeed find in reality the real-world versions of those represented entities nor if there is one-and-only-one model that actually matches exactly the data you may want to have linked to & checked against the ontology.

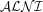 (called
(called  in [3], with PTIME subsumption), whereas the modelling language-specific profiles do not match any of the very many currently existing Description Logic languages with known computational complexity.
in [3], with PTIME subsumption), whereas the modelling language-specific profiles do not match any of the very many currently existing Description Logic languages with known computational complexity. ” DL that, as far as we know, hasn’t been investigated yet. That said, fiddling a bit by opting for unique name assumption and some constraints on cardinalities and role inclusion, it looks like
” DL that, as far as we know, hasn’t been investigated yet. That said, fiddling a bit by opting for unique name assumption and some constraints on cardinalities and role inclusion, it looks like  [4] may suffice, which is NLOGSPACE in subsumption and
[4] may suffice, which is NLOGSPACE in subsumption and 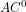 in data complexity.
in data complexity. [4] should do (also NLOGSPACE), though
[4] should do (also NLOGSPACE), though  [5] will make the formalisation better to follow (though that DL has too many features and is EXPTIME-complete).
[5] will make the formalisation better to follow (though that DL has too many features and is EXPTIME-complete).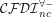 we still can capture over 96% of the elements in the ORM models of the dataset and it’s PTIME (yup, tractable) [7].
we still can capture over 96% of the elements in the ORM models of the dataset and it’s PTIME (yup, tractable) [7].
