In the previous post on building bias into your database, I outlined seven modelling tricks to build your preference into the information system. Here, I will look at some of those databases and a tool/calculation built on top of such conflict databases (the ‘dirty war index’).
Conflict databases
The US terrorism incident database at MIPT suffers from most of the afore-mentioned pitfalls, which drove a recently graduated friend, Dr. Fraser Gray, to desperation asking me if I could analyse the numbers (but, alas, the database has some inconsistencies). I have more, official, detail about the design rationale and limitations of the civil war incident databases developed by Weinstein and by Sutton. In his fascinating book Inside Rebellion [1], Weinstein has described his tailor-made incident database in Appendix B; so, although I’m going to comment on the database, I still highly recommend you read the book.
Weinstein applies organsational theory to rebel organisations in civil war settings and tests his hypotheses experimentally against case studies of Uganda, Mozambique, and Peru. As such, his self-made database was made with the following assumption in mind: “civilians are often the primary and deliberate target of combatants in civil wars… Accordingly, an appropriate indicator of the “incidence” of civil war is the use of violence against noncombatant populations.” Translated to the database focus, it is a people-centred database, not, say, target-centred. Not only deaths are counted, but also a range of violations, including mutilation, abduction, detention, looting, and rape, and victim charactersitics with name, age, sex, affilitation and affiliation groups, such as religious leaders, students, occupation of civilian, and traditional authorities (according to Appendix B).
Geography is coded only at a high level—at least, the information provided in chapter 6 that deals with the quantitative data discusses only (aggregated?) rough regions, such as Mozambique’s “north”, “centre” and “south”, but for Sendero Luminoso-Huallaga no sub-regions at all. To its merit, it has a year-by-year breakdown of the incidents, although one has no access to which type of incidents exactlyeven though they are supposed to be in the database. It does not discuss quantitatively the types of arms and the targets; it certainly makes a difference to understand the dynamics of the conflict if, say, targets like water purification plants are blown up or military bases attacked and if sophisticated ‘non-conventional arms’ are used or machetes. If we want to know that, it seems we have to redo the data collection process. No statistical analysis is performed, so that for, e.g., the size of the victim groups we get indications of ‘relatively more’, and barely even percentages or ratios to make cross-comparisons across years or across conflicts but which could have been done based on the stacked-bar charts of the (yet again aggregated) data. The huge amount of incidents marked as “unclear” for Peru only has guessed explanations, due to data collection issues (e.g., for 1987 some 500 “unclear” versus about 40 attributed to Sendero Luminoso-Nacional and 30 government)—try feeding such data into the DWI (see below). The definitions of “civilian” and “non-combatant” are not clear, not even sort of inferable as with Sutton’s database (see below).
Overall, it merely gives a rough idea of some aspects of the examined conflicts, but maybe this already suffices for comparative politics.
UPDATE (21-1-2009): Jeremy Weinstein kindly responded via email, being aware of the aggregations used in the data analysis, because they intended to serve a descriptive role, and pointing me to an effort of more detailed data collection, finer-grained analysis, and online data (in proprietary Strata format) of the conflict in Sierra Leone, which was published in American Political Science Review. That freely available paper, Handing and manhandling civilians in civil war, also gives an indication what the reader can expect of the contents in the book, and has a set of 8 hypotheses that are tested against the data (not all of them could be confirmed).
The Dirty War Index
There are people who build tools upon such conflict databases. Garbage In, Garbage Out? I will highlight one of those tools, which received extensive coverage in PLoS Medicine recently [2,3,4]: being able to calculate a “Dirty War Index” for a variety of parameters that follow the pattern of  . The cases and their aggregates to nr of cases come from the conflict’s incidents databases. Go figure. It’s not just that, but one could/would/should assume that the examples Hicks and Spagat give in their paper [3] are to illustrate, but not to invalidate, their DWI approach.
. The cases and their aggregates to nr of cases come from the conflict’s incidents databases. Go figure. It’s not just that, but one could/would/should assume that the examples Hicks and Spagat give in their paper [3] are to illustrate, but not to invalidate, their DWI approach.
Let us take their first example, the DWIs for the actors in the Colombian civil conflict as the measure  . The ‘guerillas’ (presumably FARC) have a DWI of
. The ‘guerillas’ (presumably FARC) have a DWI of 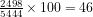 , the ‘government forces’
, the ‘government forces’  , and the ‘illegal paramilitaries’ (a pleonasm)
, and the ‘illegal paramilitaries’ (a pleonasm)  (numbers taken from the simple Colombia conflict database [5]). Hicks and Spagat explain that “Guerrillas rank 2nd in killing absolute numbers of civilians”, as if the government forces deserve a laurel for having the best (closest to 0) DWI—with a mere 1-point margin—and as if paramilitaries are independent of the government whereas it is the norm, rather than the exception, that governments tend to arrange for a third party to do the dirty work for them (with or without external funding) so as to look comparatively good in the international spotlights. Aggregating by ‘opponents of FARC’, we get a DWI of
(numbers taken from the simple Colombia conflict database [5]). Hicks and Spagat explain that “Guerrillas rank 2nd in killing absolute numbers of civilians”, as if the government forces deserve a laurel for having the best (closest to 0) DWI—with a mere 1-point margin—and as if paramilitaries are independent of the government whereas it is the norm, rather than the exception, that governments tend to arrange for a third party to do the dirty work for them (with or without external funding) so as to look comparatively good in the international spotlights. Aggregating by ‘opponents of FARC’, we get a DWI of  , which is substantially more dirty than FARC that cannot be explained away anymore by data collection biases [4]; to put it differently, FARC is in this DWI the proverbial ‘lesser of two evils’, or, if you support their cause then you could say they have good reason to be annoyed with the current violent governance in the country. This also suggest that requiring “recognition in Colombia’s paramilitary demobilization, disarmament, and reintegration process” [3] alone may not be enough to achieve durable peace for Colombians.
, which is substantially more dirty than FARC that cannot be explained away anymore by data collection biases [4]; to put it differently, FARC is in this DWI the proverbial ‘lesser of two evils’, or, if you support their cause then you could say they have good reason to be annoyed with the current violent governance in the country. This also suggest that requiring “recognition in Colombia’s paramilitary demobilization, disarmament, and reintegration process” [3] alone may not be enough to achieve durable peace for Colombians.
The other main illustration is the conflict in Northern Ireland by using two complementary DWIs: “aggressive acts (killing civilians) and endangerment to civilians (by not wearing uniforms)”. The ‘British Security Forces’ (BSF) have a “Civilian mortality DWI” of 52, the ‘Irish Republican Paramilitaries’ (IRP) 36, and the ‘Loyalist paramilitaries’ (LP) 86—note the odd naming and aggregations, e.g., are we talking IRA, or lumping the IRA together with the Real-IRA and Continuity-IRA, and all UFF, LVF…? Consulting the extensive source database, it lists 29 groups. In addition, [3]’s “number of civilian + civilian political activist” are, respectively, 190+738+873=1801, but the source’s data has 1797 civ.+ 58 civ.pol.activists = 1855, and then a series of statuses such as “ex-British army”, “ex-IRA” and so forth, who, while being “ex-” are not real civilians according to the database. Much more data for compiling your preferred DWI and preferred details or aggregates can be found here [6].
The “Attacks without uniform DWI” are “approaches 0” (BSF), “approaches 100” (IRP) and “approaches 100” (LP) without actual values to do the calculation with; nevertheless the vagaries, for the IRP they prefer the adjective “extremely high rate” but for the LP it is only “very high rate”. They try a comparatively long explanation for the nastyness of the IRP, but it is plain that the BSF and LP have the dirtiest civilian DWI and that LP killed most civilians, no matter how one wants to explain it away and dress it up with DWIs (maybe not so coincidentally, the authors are affiliated with UK institutions).
I will leave Hicks and Spagat’s “female mortality DWI” of the Arab-Israeli conflict and the “child casualty DWI” of Chechnya for the interested reader to analyse (including the term ‘unexploded ordnance’ that injured or killed children—by exploding).
Although the idea of multiple DWIs can indeed be interesting to give a rough indication, there is the real danger of misuse due to unfair sanitation of data: it can easily stimulate misinterpretation by showing some neat aggregated numbers without having to assess the source data and by brushing over the reality on the ground that a bean-counting person may not be aware of and more readily can set aside in favour of the aggregated numbers.
Hicks and Spagat do have a section on considerations, but that their two main worked-out examples with Colombia and Northern Ireland are problematic already just proves the point about possible dubious use for one’s own political agenda. Perhaps they would say the same of my alternative rendering being politically coloured, but I do not try to give it a veneer of credibility and advantages of DWIs, just that it is simple to turn around and play with the DWIs to suit one’s preferences, whichever they may be.
UPDATE (5-6-’09): a more comprehensive review of Hicks and Spagat’s paper will be published in the autumn 2009 issue of the Peace & Conflict Review.
[1] Weinstein, Jeremy M. (2007). Inside rebellion—the politics of insurgent violence. Cambridge University Press.
[2] Sondorp E (2008 ) A new tool for measuring the brutality of war. PLoS Med 5(12): e249. doi:10.1371/journal.pmed.0050249
[3] Hicks MH-R, Spagat M (2008 ) The Dirty War Index: A public health and human rights tool for examining and monitoring armed conflict outcomes. PLoS Med 5(12): e243. doi:10.1371/journal.pmed.0050243.
[4] Taback N (2008 ) The Dirty War Index: Statistical issues, feasibility, and interpretation. PLoS Med 5(12): e248. doi:10.1371/journal.pmed.0050248.
[5] The numbers originate from CERAC’s Colombia conflict database as reported in [3]; both Hicks and Spagat are research associates of CERAC; database available after registration, which has substantially less types of information and less explanation than Sutton’s [6] database.
[6] CAIN Web Service as reported in [3]; database freely available, including data, querying, and design and data collection choices.



