There are manifold logic-based reconstructions of the main conceptual data modelling languages in a ‘gazillion’ of logics. The reasons for pursuing this line of work are good. In case you wonder, consider:
- Automated reasoning over a conceptual data model to improve their quality and avoid bugs; e.g., an empty database table due to an inconsistency in the model (unsatisfiable class). Instead of costly debugging, one can catch it upfront.
- Designing and executing queries with the model’s vocabulary cf. putting up with how the data is stored with its typically cryptic table and column names.
- Test data generation in automation of software engineering.
- Use it as ‘background knowledge’ during the query compilation stage (which helps optimizing it, so better performance querying a database).
Most of the research efforts on formalizing the conceptual data modelling languages have gone to capturing as much as possible of the modelling language, and therewith aiming to solve the first use case scenario. Runtime usage of conceptual models, i.e., use case scenarios 2-4 above, is receiving some attention, but it brings with it its own set of problems: which trade-offs are the best? That is, we know we can’t have both the modelling languages in their full glory formalised on some arbitrary (EXPTIME or undecidable) logic and have scalable runtime performance. But which subset to choose? There are papers where (logician) authors state something like ‘you don’t need keys in ER, so we ignore those’ or ‘let’s skip ternaries, as most relationships are binary anyway’ or ‘we sweep those pesky aggregation associations under the carpet’ or ‘hierarchies, disjointness and completeness are certainly important’. Who’s right? Or is neither one of them right?
So, we had all that data of the 101 UML, ER, EER, ORM, and ORM2 models analysed (see previous post and [1]). With that, we could construct evidence-based profiles based on the features that are actually used by modellers, rather than constructing profiles based on gut feeling or on one’s pet logic. We specified a core profile and one for each family of the conceptual data modelling languages under consideration (UML Class Diagrams, ER/EER, and ORM/ORM2). The details of the outcome can be found in our recently accepted paper “Evidence-based Languages for Conceptual Data Modelling Profiles” [1] that has been accepted at the 19th Conference on Advances in Databases and Information Systems (ADBIS’15), that will take place from September 8-12 in Poitiers, France. As with the other recent posts on conceptual data models, also this paper was co-authored with Pablo Fillottrani and is an output of our DST/MINCyT-funded bi-lateral project on the unification of conceptual data modelling languages (project overview).
To jump to the short answer: the core profile can be represented in 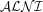

Now how we got into that situation. There are some formalization options to consider first, which can affect the complexity of the logic. Notably, 1) whether to use inverses or qualified number restrictions, and 2) whether to go for DL role components for UML’s association ends/ORM’s roles/ER’s relationship components with a 1:1 mapping, or to ignore that and formalise the associations/fact types/relationships only (and how to handle that choice then). Extending a logic language with inverses tends to be less costly computationally cf. qualified number restrictions, so we chose the former. The latter is more complicated to handle regardless the choice, which is partially due to the fact that they are surface aspects of an underlying difference in ontological commitment as to what relations are—so-called standard view versus positionalist—and how it is represented in the models (see discussion in the paper). For the core profile, the dataset of conceptual models justified binaries + standard view representation. In addition to that, the core profile has classes, attributes, mandatory and arbitrary (unqualified) cardinality, class subsumption, and single identification. That set covers 87.57% of all the entities in the models in the dataset (91.88% of the UML models, 73.29% of the ORM models, and 94.64% of the ER/EER models). Note there’s no disjointness or completeness (there were too few of them to merit inclusion) and no role and relationship subsumption, so there isn’t much one can deduce automatically, which is a bit of a bummer.
The UML profile extends the core only slightly, yet it covers 99.44% of the elements in the UML diagrams of the dataset: add cardinality on attributes, attribute value constraints, subsumption for DL roles (UML associations), and aggregation (they are plain associations since UML v2.4.1). This makes a “

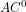
For ER/EER, we need to add to the core the following to make it to 99.06% coverage: composite and multivalued attribute (remodelled), weak entity type with its identification constraint, ternaries, associative entity types, and multi-attribute identification. With some squeezing and remodelling things a bit (see paper), 

Last, the ORM/ORM2 profile, which is the largest to achieve a high coverage (98.69% of the elements in the models in the data set): the core profile + subsumption on roles (DL role components) and fact types (DL roles), n-aries, disjointness on roles, nested object types, value constraints, disjunctive mandatory, internal and external uniqueness, external identifier (compound reference scheme). There’s really no way to avoid the roles, n-aries, and disjointness. There’s no exactly fitting DL for this cocktail of features, though 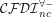
The discussion section of the paper answers the research questions we posed at the beginning of the investigation and reflects on not only missing features, but also ‘useless’ ones. Perhaps we won’t make a lot of friends discussing ‘useless’ features, especially when some authors investigated exactly those features. Anyway, here it goes. Really, nominal are certainly not needed (and computationally costly to boot). We can only guess why there were so few disjointness and completeness constraints in the data set, and even when they were present, they were in the few models we got from textbooks (see data set for sources of the models); true, there weren’t a lot of class hierarchies, but still. The other thing that was a bit of a disappointment was that the relational properties weren’t used a lot. Looking at the relationships in the models, there were certainly opportunities for transitivity and more irreflexivity declarations. One of our current conjectures is that they have limited implementation support, so maybe modellers don’t see the point of adding such constraints; another could be that an ‘average modeller’ (whatever that means) doesn’t quite understand all the 11 that are available in ORM2.
Overall, while a bit disappointing for the use case scenario of reasoning over conceptual data models for inconsistency management, the results are actually very promising for runtime usage of conceptual data models. Maybe that of itself will generate more interest from industry in doing that analysis step before implementing a database or software application: instead of developing a conceptual data model “just for documentation and dust-gathering”, you’ll have one that also will add more, new, better advanced features to your application.
References
[1] Keet, C.M., Fillottrani, P.R. An analysis and characterisation of publicly available conceptual models. 34th International Conference on Conceptual Modeling (ER’15). Springer LNCS. 19-22 Oct, Stockholm, Sweden. (in print)
[2] Fillottrani, P.R., Keet, C.M. Evidence-based Languages for Conceptual Data Modelling Profiles. 19th Conference on Advances in Databases and Information Systems (ADBIS’15). Springer LNCS. Poitiers, France, Sept 8-11, 2015. (in print)
[3] Donini, F., Lenzerini, M., Nardi, D., Nutt, W. Tractable concept languages. In: Proc. of IJCAI’91. vol. 91, pp. 458-463. 1991.
[4] Artale, A., Calvanese, D., Kontchakov, R., Zakharyaschev, M. The DL-Lite family and relations. Journal of Artificial Intelligence Research, 2009, 36:1-69.
[5] Calvanese, D., De Giacomo, G., Lenzerini, M. Identification constraints and functional dependencies in Description Logics. In: Proc. of IJCAI’01, pp155-160, Morgan Kaufmann.
[6] Toman, D., Weddell, G. On adding inverse features to the Description Logic 
[7] Fillottrani, P.R., Keet, C.M., Toman, D. Polynomial encoding of ORM conceptual models in

Pingback: The ontology-driven unifying metamodel of UML class diagrams, ER, EER, ORM, and ORM2 | Keet blog
Pingback: Fruitful ADBIS’15 in Poitiers | Keet blog
Pingback: Experimentally-motivated non-trivial intermodel links between conceptual models | Keet blog