It all sounded so easy… We have a pretty good and stable idea about part-whole relations and their properties (see, e.g., [1]), we know how to ‘verbalise’/generate a natural language sentence from basic description logic axioms with object properties that use simple verbs [2], like 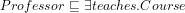
What it ended up to be, is that notions of ‘part’ in isiZulu are at times less precise and other times more precise compared to the taxonomy of part-whole relations. This interfered with devising the sentence generation patterns, it pushed the number of ‘elements’ to deal with in the language up to 13 constituents, and there was no way to avoid proper phonological conditioning. We already could handle quantitative, relative, and subject concords, the copulative, and conjunction, but what had to be added were, in particular, the possessive concord, locative affixes, a preposition (just the nga in this context), epenthetic, and the passive tense (with modified final vowel). As practically every element has to be ‘completed’ based on the context (notably the noun class), one can’t really speak of a template-based approach anymore, but a bunch of patterns and partial grammar engine instead. For instance, plain parthood, structural parthood, involvement, membership all have:
- (‘each whole has some part’)
dwa
- (‘each part is part of some whole’)
ingxenye
dwa





There are a couple of noteworthy things here. First, the whole-part relation does not have one single string, like a ‘has part’ in English, but it is composed of the subject concord (SC) for the noun class (nc) of the noun that play the role of the whole ( W ) together with the phonologically conditioned conjunction na- ‘and’ (the “SC-CONJ”, above) and glued onto the noun of the entity that play the role of the part (P). Thus, the surface realisation of what is conceptually ‘has part’ is dependent on both the noun class of the whole (as the SC is) and on the first letter of the name of the part (e.g., na-+i-=ne-). The ‘is part of’ reading direction is made up of ingxenye ‘part’, which is a noun that is preceded with the copula (COP) y– and together then amounts to ‘is part’. The ‘of’ of the ‘is part of’ is handled by the possessive concord (PC) of ingxenye, and with ingxenye being in noun class 9, the PC is ya-. This ya- is then made into one word together with the noun for the object that plays the role of the whole, taking into account vowel coalescence (e.g., ya-+u-=yo-). Let’s illustrate this with heart (inhliziyo, nc9) standing in a part-whole relation to human (umuntu, NC1), with the ‘has part’ and ‘is part of’ underlined:
- bonke abantu banenhliziyo eyodwa ‘All humans have as part at least one heart’
- The algorithm, in short, to get this sentence from, say
: 1) it looks up the noun class of umuntu (nc1); 2) it pluralises umuntu into abantu (nc2); 3) it looks up the quantitative concord for universal quantification (QCall) for nc2 (bonke); 4) it looks up the SC for nc2 (ba); 5) then it uses the phonological conditioning rules to add na- to the part inhliziyo, resulting in nenhliziyo and strings it together with the subject concord to banenhliziyo; 6) and finally it looks up the noun class of inhliziyo, which is nc9, and from that it looks up the relative concord (RC) for nc9 (e-) and the quantitative concord for existential quantification (QC) for nc9 (being yo-), and strings it together with –dwa to eyodwa.
- The algorithm, in short, to get this sentence from, say
- zonke izinhliziyo ziyingxenye yomuntu oyedwa ‘All hearts are part of at least one human’
- The algorithm, in short, to get this sentence from
: 1) it looks up the noun class of inhliziyo (nc9); 2) it pluralises inhliziyo to izinhliziyo (nc10); 3) it looks up the QCall for nc10 (zonke); 4) it looks up the SC for nc10 (zi-), takes y- (the COP) and adds them to ingxenye to form ziyingxenye; 5) then it uses the phonological conditioning rules to add ya- to the whole umuntu, resulting in yomuntu; 6) and finally it looks up the noun class of umuntu, which is nc1, and from that the RC for nc10 (o-) and the QC for nc10 (being ye-), and strings it together with –dwa to oyedwa.
- The algorithm, in short, to get this sentence from
For subquantities, we end up with three variants: one for stuff-parts (as in ‘urine has part water’, still with ingxenye for ‘part’), one for portions of solid objects (as in ‘tissue sample is a subquantity of tissue’ or a slice of the cake) that uses umunxa instead of ingxenye, and one ‘spatial’ notion of portion, like that an operating theatre is a portion of a hospital, or the area of the kitchen where the kitchen utensils are is a portion of the kitchen, which uses isiqephu instead of ingxenye. Umunxa is in nc3, so the PC is wa- so that with, e.g., isbhedlela ‘hospital’ it becomes wesibhedlela ‘of the hospital’, and the COP is ng- instead of y-, because umunxa starts with an u. And yet again part-whole relations use locatives (like the containment type of part-whole relation). The paper has all those sentence generation patterns, examples for each, and explanations for them.
The meronymic part-whole relations participation and constitution have added aspects for the verb, such as generating the passive for ‘constituted of’: –akha is ‘to build’ for objects that are made/constituted of some matter in some structural sense, else –enza is used. They are both ‘irregular’ in the sense that it is uncommon that a verb stem starts with a vowel, so this means additional vowel processing (called hiatus resolution in this case) to put the SC together with the verb stem. Then, for instance za+akhiwe=zakhiwe but u+akhiwe=yakhiwe (see rules in paper).
Finally, this was not just a theoretical exercise, but it also has been implemented. I’ll readily admit that the Python code isn’t beautiful and can do with some refactoring, but it does the job. We gave it 42 test cases, of which 38 were answered correctly; the remaining errors were due to an ‘incomplete’ (and unresolvable case for any?) pluraliser and that we don’t know how to systematically encode when to pick akha and when enza, for that requires some more semantics of the nouns. Here is a screenshot with some examples:

The ‘wp’ ones are that a whole has some part, and the ‘pw’ ones that the part is part of the whole and, in terms of the type of axiom that each function verbalises, they are of the so-called ‘all some’ pattern.
The source code, additional files, and the (slightly annotated) test sentences are available from the GENI project’s website. If you want to test it with other nouns, please check whether the noun is already in nncPairs.txt; if not, you can add it, and then invoke the function again. (This remains this ‘clumsily’ until we make a softcopy of all isiZulu nouns with their noun classes. Without the noun class explicitly given, the automatic detection of the noun class is not, and cannot be, more than about 50%, but with noun class information, we can get it up to 90-100% correct in the pluralisation step of the sentence generation [4].)
References
[1] Keet, C.M., Artale, A. Representing and Reasoning over a Taxonomy of Part-Whole Relations. Applied Ontology, 2008, 3(1-2):91-110.
[2] Keet, C.M., Khumalo, L. Basics for a grammar engine to verbalize logical theories in isiZulu. 8th International Web Rule Symposium (RuleML’14), A. Bikakis et al. (Eds.). Springer LNCS vol. 8620, 216-225. August 18-20, 2014, Prague, Czech Republic.
[3] Keet, C.M., Khumalo, L. On the verbalization patterns of part-whole relations in isiZulu. 9th International Natural Language Generation conference (INLG’16), September 5-8, 2016, Edinburgh, UK. (in print)
[4] Byamugisha, J., Keet, C.M., Khumalo, L. Pluralising Nouns in isiZulu and Related Languages. 17th International Conference on Intelligent Text Processing and Computational Linguistics (CICLing’16), Springer LNCS. April 3-9, 2016, Konya, Turkey. (in print)

Pingback: Brief report on the INLG16 conference | Keet blog